Why token incentives improve data quality
Build a Token-Incentivized Data Labeling Workflow for AI issues are easier to solve when you separate the symptom from the device itself. A frozen touchscreen, a blank display, broken Bluetooth, and a slow map update can feel like the same failure, but they point to different causes. Write down what still works, what stopped responding, and whether the problem appears after startup, after a software update, or only after pairing a phone. Do the first pass while the car or device is parked, powered normally, and connected to a stable signal. If only one app is frozen, close that path before treating the whole system as broken. If core controls, driver information, warning lights, or safety features are involved, stop treating it as a cosmetic infotainment issue and move to the official support path. This distinction keeps the reset from becoming a ritual. The goal is not to reboot repeatedly; it is to prove whether the fault is temporary software lag, a connection problem, outdated firmware, accessory interference, or something that needs service documentation.
The simplest way to use this section is to keep the setup small, verify each change, and record the stable configuration before adding optional accessories.
Step 1: Define labeling tasks and quality metrics
Before deploying any smart contract, you must establish a rigid framework for what constitutes a "good" label. Token incentives amplify both quality and noise; without clear boundaries, annotators will game the system by submitting low-effort responses to maximize volume. This section outlines the three foundational steps to defining your task schema, setting consensus rules, and selecting the appropriate token standard.
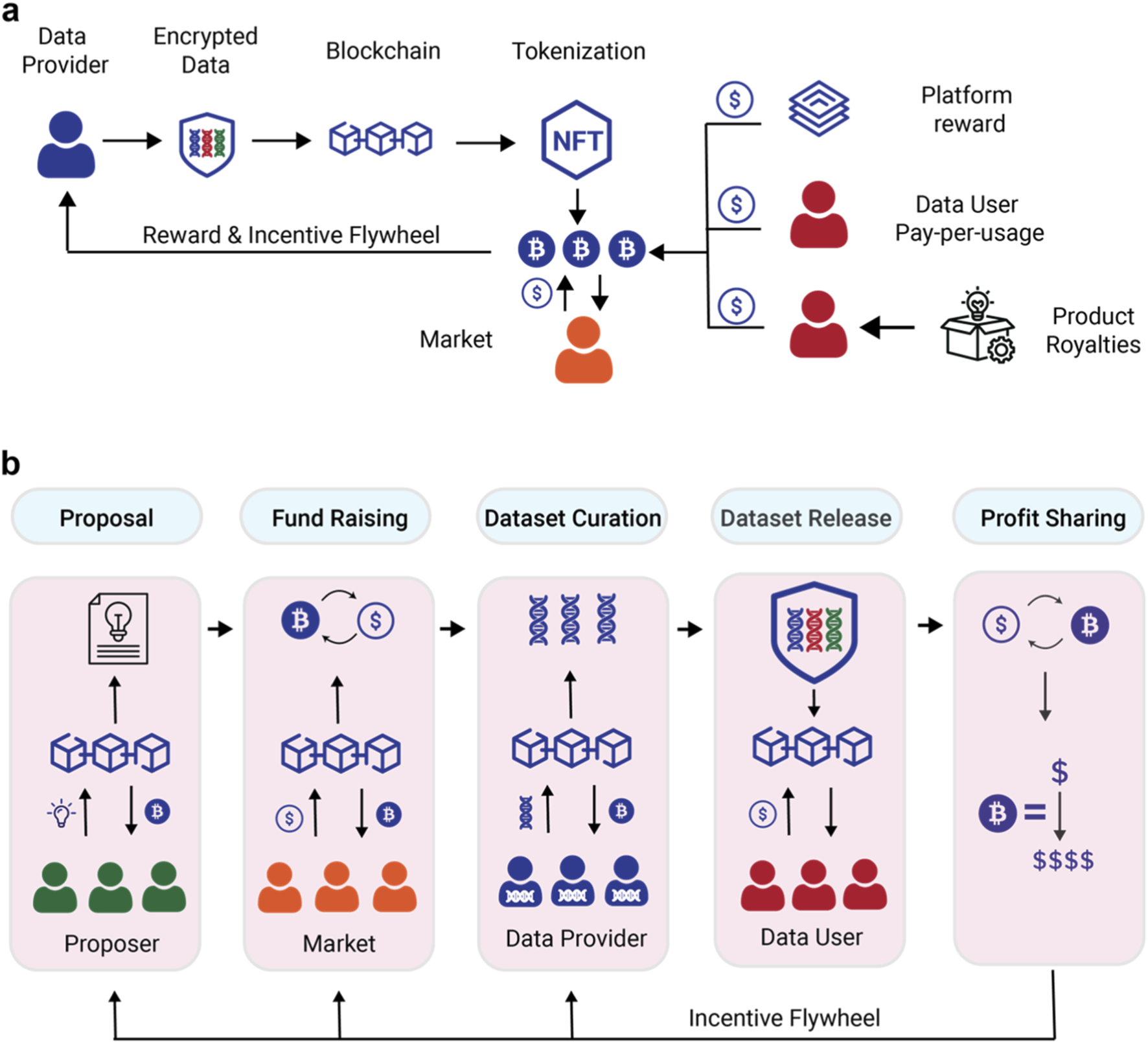
Start by creating a detailed annotation guideline document. This is not a suggestion box; it is the legal code for your human workforce. Define every possible class, edge case, and exclusion criteria explicitly. For example, if you are labeling sentiment, specify how to handle sarcasm or neutral statements. Ambiguity here leads to inconsistent data, which directly reduces model performance regardless of the token reward structure. Reference official ML guidelines, such as Google’s Data Labeling documentation, to ensure your schema aligns with industry standards for training high-quality datasets.
Token rewards should be tied to consensus, not just submission. Implement a Kappa-based or simple majority voting system where multiple annotators label the same instance. Only release tokens when a pre-defined threshold (e.g., 2 out of 3 annotators agree) is met. This mechanism filters out random or malicious inputs. Research into decentralized data platforms, such as those leveraging Ethereum smart contracts for verification IEEE Xplore, demonstrates that consensus-driven reward distribution significantly reduces the cost of quality control by automating the rejection of outlier labels.
Choose a token standard that fits your volume and fee structure. ERC-20 tokens are standard for most decentralized data labeling platforms due to their widespread compatibility with wallets and exchanges. However, for high-frequency, low-value micropayments, consider Solana-based tokens to minimize gas fees that could otherwise eat into annotator earnings. The choice impacts the user experience: high fees discourage casual contributors, while low fees enable fine-grained incentives for small, precise tasks. Evaluate the trade-off between transaction speed and ecosystem liquidity before finalizing your incentive layer.
By locking in these three elements, you create a predictable environment where annotators know exactly how to earn and you know exactly what data you will receive. This clarity is the prerequisite for any successful token-incentivized workflow.
Step 2: Deploy smart contracts for escrow and rewards
Build a Token-Incentivized Data Labeling Workflow for AI works best as a clear sequence: define the constraint, compare the realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative. After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.
Onboard annotators and manage consensus
The transition from smart contract deployment to active data labeling requires a structured onboarding flow. Before distributing tasks, you must verify that annotators understand the specific schema for your token-incentivized data labeling workflow. This step ensures that the human-in-the-loop component aligns with the machine learning model's requirements, reducing the noise that degrades training data quality.
Recruit and verify labelers
Start by recruiting annotators from decentralized talent pools or community forums. Use a brief qualification test to assess their ability to follow complex labeling guidelines. This verification step is critical because the accuracy of your AI model depends entirely on the precision of the input data. Incentivize high-quality submissions by offering bonus tokens for annotators who consistently pass validation checks.
Distribute tasks via smart contracts
Once verified, distribute tasks automatically through your smart contract. The contract should assign data samples based on the annotator’s skill level and current availability. To prevent bottlenecks, split large datasets into smaller, manageable batches. This approach allows the system to scale efficiently as more annotators join the network, ensuring a steady flow of labeled data for your AI training pipeline.
Implement consensus mechanisms
To determine payout accuracy, implement a consensus mechanism that aggregates multiple labels for the same data point. If annotators disagree, the system can flag the sample for review by a senior expert or use a majority-vote algorithm to determine the final label. This process minimizes bias and error, ensuring that only high-quality, consensus-driven data is used to train your AI models. The integrity of your token economy relies on this rigorous validation step.
Common pitfalls in decentralized labeling
Build a Token-Incentivized Data Labeling Workflow for AI works best as a clear sequence: define the constraint, compare the realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative. After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.
| Factor | What to check | Why it matters |
|---|---|---|
| Fit | Match the option to the primary use case. | A good deal still fails if it does not fit the job. |
| Condition | Verify age, wear, and service history. | Hidden condition issues erase upfront savings. |
| Cost | Compare purchase price with likely upkeep. | The cheapest option is not always the lowest-cost option. |
Verify data quality before model training
Before you feed your dataset into a fine-tuning pipeline, you must audit the labeled data to ensure the token incentives actually drove accuracy. A token-incentivized data labeling workflow introduces unique validation challenges, particularly around sybil attacks and low-effort submissions. This section walks through the final checks required to certify your dataset.
Calculate the inter-annotator agreement for each data point. In token-incentivized systems, high reward frequency can sometimes mask low-quality output. Require a consensus rate above 95% for critical training examples. If agreement drops, flag those samples for manual review before they enter the model training phase. This step ensures that the tokens paid out correspond to reliable human judgment, not just volume.
Token rewards create a financial incentive for bad actors to farm submissions using automated scripts. Run your dataset through sybil detection algorithms to identify clusters of submissions from similar IP addresses or device fingerprints. Remove any flagged accounts and their associated data points. This protects the integrity of your training corpus from injected noise or adversarial inputs.
Ensure the labeled format matches the exact input structure required by your target LLM. Mismatched schemas cause immediate pipeline failures during fine-tuning. Cross-check field names, data types, and tokenization boundaries against your model’s configuration. A simple schema mismatch can render weeks of labeling efforts useless.

Review the distribution of labels over time. If the token incentive structure changed mid-campaign, you may see a sudden shift in how labelers interpret ambiguous cases. Detect this drift by sampling data from the beginning, middle, and end of the collection period. Normalize any inconsistencies to maintain a uniform training signal.
Frequently asked questions about token labeling
Is data labeling a good career?
Data annotation jobs are legitimate and essential to AI growth. Humans-in-the-loop provide the high-quality labeled data that large tech companies and startups rely on to train their models. It is a viable entry point into the machine learning industry, though roles are evolving toward more complex oversight tasks.
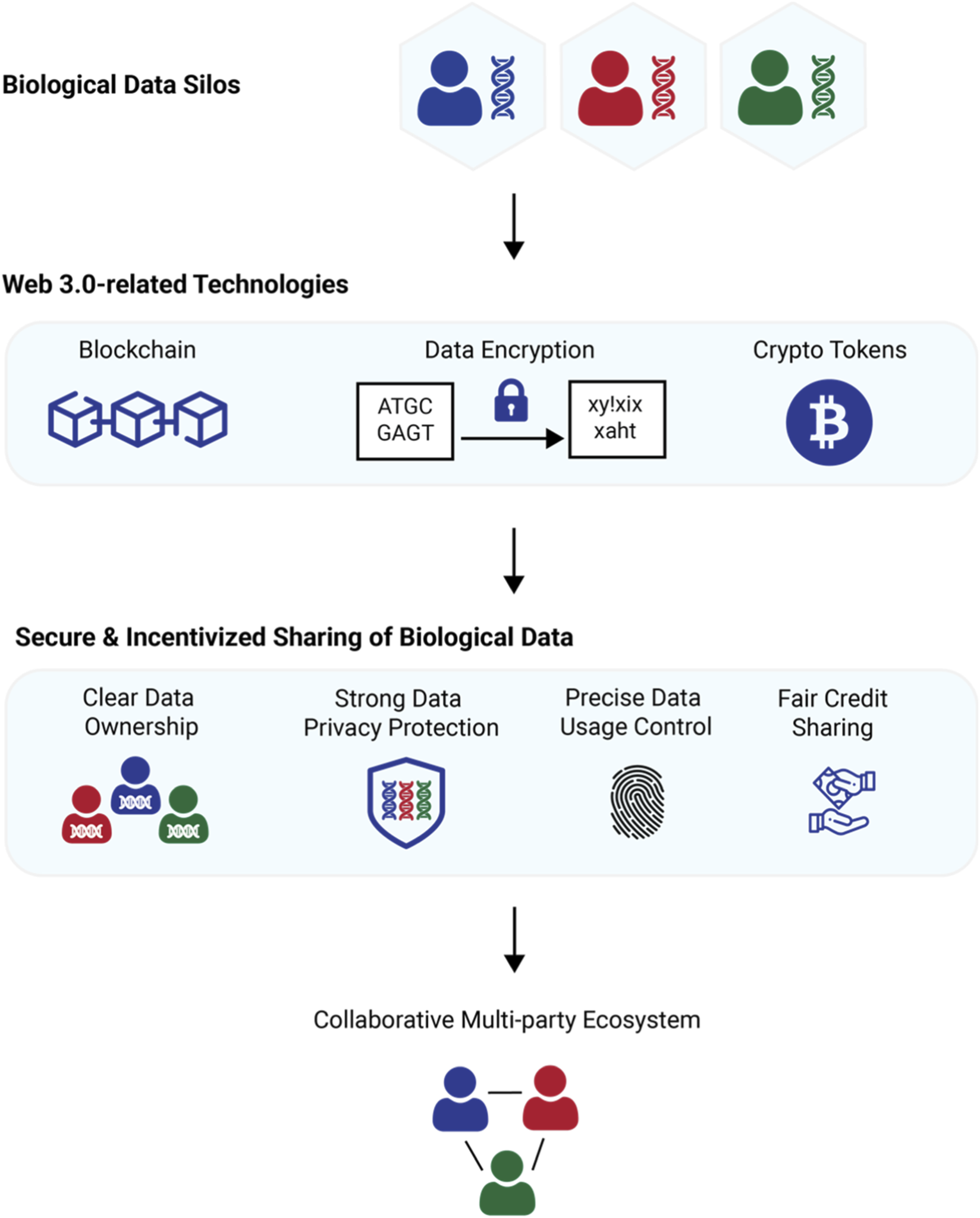
What are the benefits of data tokenization?
Tokenization increases security by replacing sensitive data with non-sensitive equivalents. This prevents businesses from capturing or storing raw sensitive information in internal databases, safeguarding systems from breaches. In the context of labeling, it allows teams to share and process data without exposing private user details.
How does data labeling work?
Data labeling annotates raw data with meaningful tags, providing context and categorization for machine learning models. These labels serve as essential guides, enabling models to interpret data effectively. The process typically involves uploading raw assets, applying tags via a platform, and verifying accuracy before training.
How do token incentives work in labeling?
Token incentives reward users for contributing to the blockchain network, such as by publishing blocks or validating data. This mechanism aligns participant interests with network health, encouraging high-quality contributions to the labeling workflow through cryptographic rewards rather than traditional fiat payments.
No comments yet. Be the first to share your thoughts!