Set up the smart contract foundation
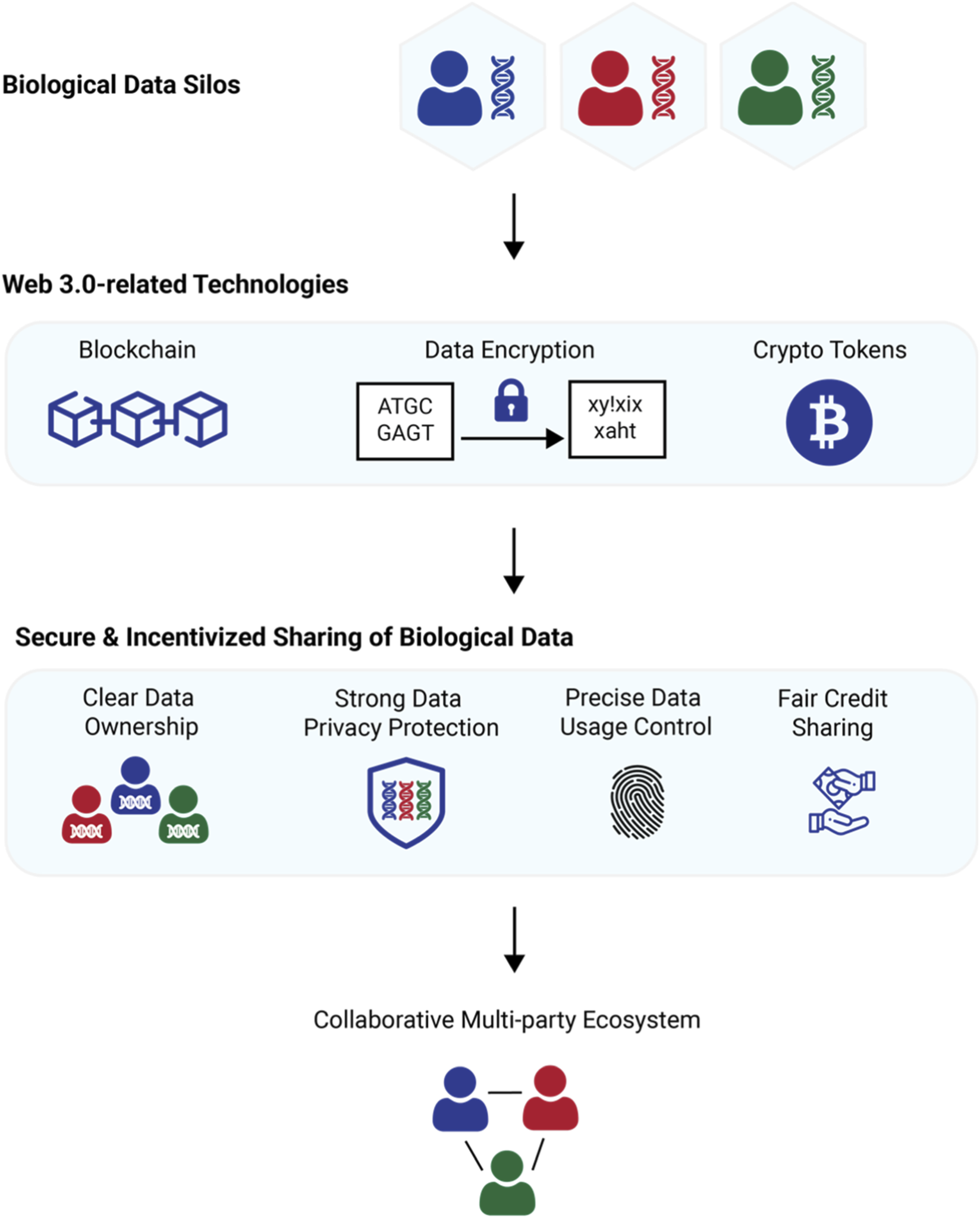
Before collecting a single label, you must deploy the economic layer that rewards annotators. This foundation consists of two main parts: an ERC-20 token for payments and a smart contract that automates distribution. Building this first ensures that every label submitted can be traced and paid out without manual intervention.
Deploy the ERC-20 reward token
Start by deploying a standard ERC-20 token on your target blockchain. This token serves as the currency for your labeling pipeline. You can choose a volatile cryptocurrency or a stablecoin. Using a stablecoin is often safer for annotators, as it prevents their earnings from losing value between the time they finish work and the time they are paid. This stability reduces churn and keeps your workforce consistent.
Build the reward distribution contract
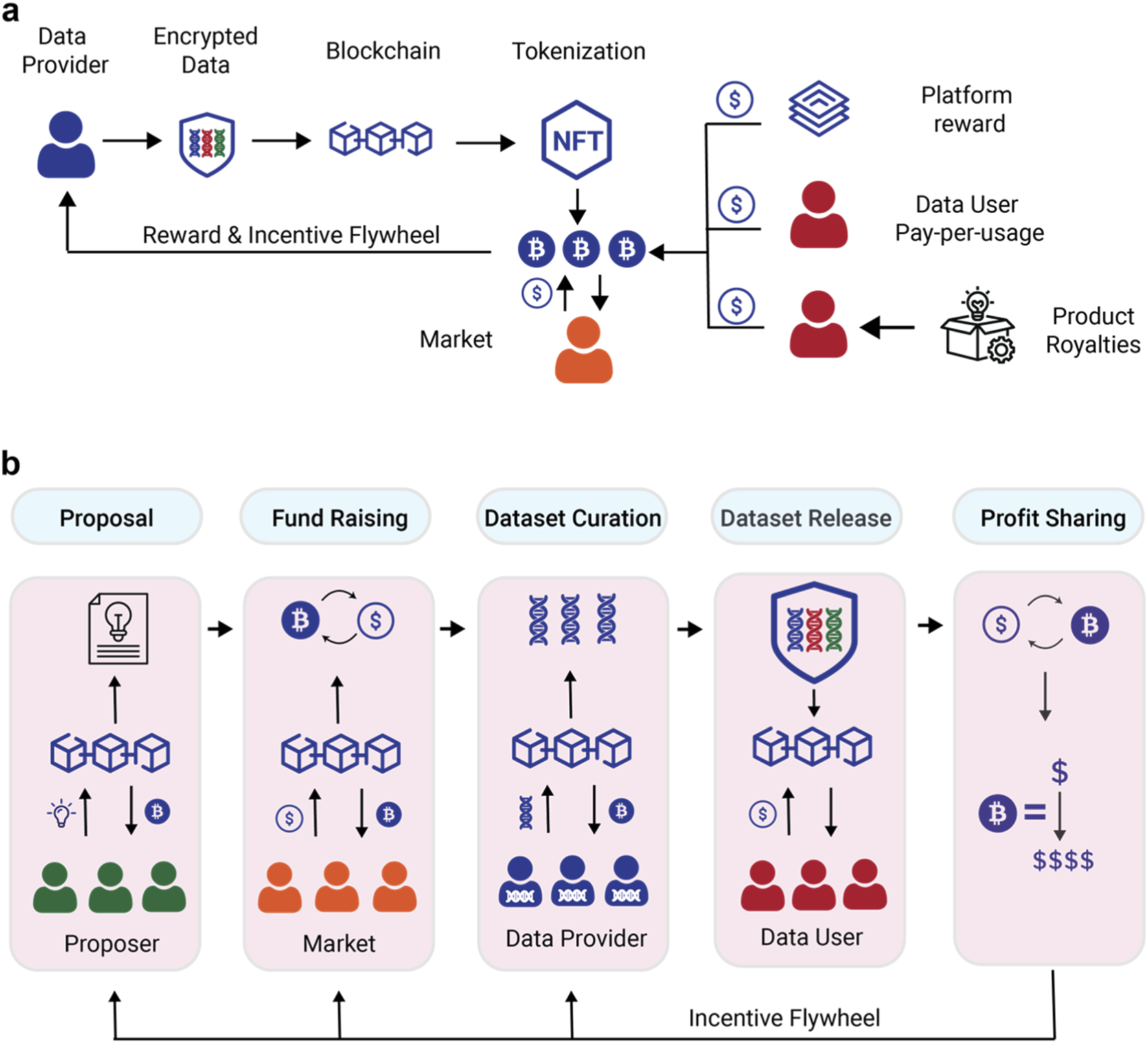
Next, deploy the smart contract that holds the token supply and manages payouts. This contract needs functions to assign rewards for completed tasks and to allow annotators to claim their earnings. The logic should verify that a label has been approved before releasing funds. This automation removes the need for a central treasurer and ensures transparency. Researchers have shown that such decentralized platforms improve security and reduce overhead compared to traditional centralized labeling services 1.
Verify contract security
Because you are handling real value, security is non-negotiable. Test your contracts on a testnet first. Ensure that only authorized functions can mint tokens or pause the contract. Consider having a third-party audit firm review your code if the budget allows. A secure foundation prevents exploits that could drain the reward pool and destroy trust in your platform.
Define quality metrics and consensus rules
Before you can distribute tokens for labeled data, you must program the logic that determines when a label is "good" enough to trigger a reward. This requires establishing clear consensus rules that balance data accuracy with the frequency of payouts.
The most common approach is majority voting. In this system, multiple annotators label the same data point. If a certain percentage of them agree, the label is accepted. This method is cost-effective and works well for straightforward tasks, such as basic image classification or sentiment analysis. However, it can fail if a group of bad actors colludes to produce incorrect labels.
For higher-stakes data, expert verification is often necessary. A trusted expert reviews a sample of the work, or serves as the final arbiter in case of disagreement. This ensures high precision but significantly increases operational costs and slows down the pipeline. You must decide which level of accuracy your specific use case demands.
| Mechanism | Accuracy Level | Reward Frequency | Best For |
|---|---|---|---|
| Majority Voting | Medium | High | Simple, repetitive tasks |
| Expert Verification | High | Low | Complex, high-value data |
| Weighted Voting | Variable | Medium | Annotators with proven track records |
| Random Audit | Variable | Medium | Ongoing quality control |
Token incentives can be dynamically adjusted based on these quality metrics. If the consensus rule detects a high rate of error, the system can automatically reduce rewards for those annotators or require additional verification steps. This creates a feedback loop that continuously improves the overall quality of the dataset.
| Mechanism | Accuracy | Reward Frequency |
|---|---|---|
| Majority Voting | Medium | High |
| Expert Verification | High | Low |
| Weighted Voting | Variable | Medium |
| Random Audit | Variable | Medium |
Connect the Annotation Interface
To make a token-incentivized data labeling pipeline functional, you must bridge the gap between the annotator’s frontend and the blockchain backend. This integration ensures that every submitted label triggers a smart contract event, instantly crediting the user’s wallet. Without this connection, the incentive loop breaks, and annotators have no immediate proof of their contribution.
1. Implement Wallet Authentication
Start by integrating a Web3 wallet provider like MetaMask or WalletConnect into your labeling dashboard. This step verifies the annotator’s identity and links their session to a specific blockchain address. Most frontend frameworks have official libraries for this, such as wagmi or ethers.js. When a user clicks "Connect," their wallet signs a challenge message, allowing your backend to trust their identity without storing sensitive private keys. This non-custodial approach is standard for decentralized platforms, as highlighted by industry analyses of crypto-powered marketplaces.
2. Build the Label Submission API
Create a secure API endpoint on your backend that accepts labeling data (e.g., bounding boxes, text tags, or classifications). Before this data reaches your AI training pipeline, it must be cryptographically signed by the annotator’s wallet. This signature proves who submitted the data and prevents tampering. The API should validate the signature against the user’s public address, ensuring only authenticated users can submit work. This step transforms raw user input into verifiable on-chain evidence.
3. Trigger the Smart Contract
Once the backend validates the label, it calls a function on your reward smart contract. This function records the annotation ID, the annotator’s address, and the task difficulty. The smart contract then calculates the reward amount based on your predefined tokenomics model. This process is often gamified to encourage consistency, as seen in platforms like Sapien, which use blockchain rewards to ensure high-quality, accurate notations. The transaction is broadcast to the network, and the user receives a transaction hash.
4. Display Real-Time Balance Updates
The frontend must listen to blockchain events to update the user’s UI instantly. Use a WebSocket connection or a polling service to watch for RewardClaimed or LabelSubmitted events from the contract. When an event fires, update the user’s token balance in the dashboard header without requiring a page refresh. This immediate feedback loop is critical for user retention; seeing your token count rise confirms the system is working and motivates continued participation.
5. Handle Transaction Failures Gracefully
Blockchain transactions can fail due to insufficient gas, network congestion, or smart contract errors. Your interface must handle these states explicitly. If a submission fails, display a clear error message with the transaction hash so the annotator can investigate on a block explorer. Never silently drop submissions. Providing a way for users to retry or contact support maintains trust in the platform’s reliability. A robust error handling strategy is essential for high-stakes data labeling operations where accuracy and uptime are paramount.
Audit data quality before model training
Before feeding your labeled dataset into the training loop, you must verify that the on-chain records accurately reflect the off-chain data. Token-incentivized pipelines introduce a specific risk: workers may prioritize speed over accuracy to maximize their earnings. This "noise" can degrade model performance just as effectively as biased sampling.
Start by cross-referencing the immutable transaction logs with the actual data payload. Ensure that every label submitted corresponds to a valid, unaltered data point. If your platform uses a decentralized architecture like the Decentralized Data Labeling Platform (DDLP) described in recent IEEE research, verify that the smart contract hashes match the stored metadata exactly. Any mismatch indicates potential tampering or a failed submission that was incorrectly marked as complete.
Next, run a statistical sanity check on the label distribution. Look for anomalies such as sudden spikes in confidence scores or uniform responses across diverse input samples. These patterns often signal bot activity or coordinated gaming of the token reward system. You should also validate that the workers who submitted the highest-value labels have a consistent track record of accuracy on previous tasks.
Finally, establish a clear threshold for rejection. If the noise level exceeds your acceptable margin, pause the pipeline and re-label the affected segment. It is far cheaper to reject low-quality tokens after validation than to retrain a model with corrupted data.
Common pitfalls in decentralized labeling
Token-incentivized systems introduce distinct security risks that centralized platforms do not face. The primary danger is the sybil attack, where bad actors create multiple fake identities to harvest rewards without providing quality work. Without strict identity verification, these "bot farms" can flood the pipeline with low-quality or adversarial labels, corrupting the training data and wasting the project's budget.
To mitigate this, implement a reputation-based staking mechanism. Require annotators to lock a small amount of tokens before accepting tasks. If their labels are flagged as incorrect by consensus or expert review, a portion of their stake is slashed. This economic penalty discourages low-effort gaming and ensures that participants have skin in the game.
Another pitfall is the "race to the bottom" in quality. When rewards are fixed per task, annotators may rush through complex labeling jobs to maximize volume. To counter this, use dynamic reward scaling that adjusts payouts based on inter-annotator agreement scores. High-quality, consistent contributors should earn significantly more than those with low accuracy, aligning financial incentives with data integrity.
Finally, ensure your smart contracts are audited by reputable firms. Vulnerabilities in the reward distribution logic can be exploited to drain funds or manipulate label outcomes. Regular audits and transparent on-chain governance for parameter adjustments help maintain trust and prevent systemic failures in your labeling pipeline.
Frequently asked: what to check next
Work through The to Token-Incentivized Data Labeling

No comments yet. Be the first to share your thoughts!