Choose the right token standard
Selecting the correct token standard is the first technical decision in building a token-incentivized data labeling pipeline. Your choice dictates how quickly annotators get paid and how much of the dataset budget goes to gas fees rather than human labor. For high-volume, low-value tasks like bounding box drawing or text classification, transaction speed and cost are the primary constraints.
ERC-20 tokens operate on Ethereum or EVM-compatible chains. They are mature and widely supported by existing wallet infrastructure, making them ideal for projects that require strict compliance or integration with existing DeFi protocols. However, Ethereum mainnet fees can be prohibitive for micro-incentives. If you choose ERC-20, you must layer on a rollup or sidechain to keep costs viable for data annotation work.
Solana offers a different architecture designed for high throughput. Its micropayment capabilities allow for near-instant settlements with fractions of a cent in fees. This makes Solana particularly attractive for decentralized data labeling platforms where annotators perform thousands of small tasks daily. The transparency of the Solana blockchain ensures that every annotation trigger and reward distribution is publicly verifiable without clogging the network.
ERC-20 vs. Solana for Data Labeling
The following comparison highlights the trade-offs between ERC-20 and Solana for token-incentivized data labeling workflows.
| Feature | ERC-20 (EVM) | Solana |
|---|---|---|
| Transaction Speed | 1-15 seconds (L1) / <2s (Rollups) | <1 second |
| Typical Gas Cost | $0.01 - $5.00+ (varies by chain) | <$0.001 |
| Ecosystem Maturity | High; widely adopted wallets and SDKs | Growing; specialized payment channels |
| Best Use Case | High-value tasks; compliance-heavy projects | High-volume micropayments; real-time feedback |
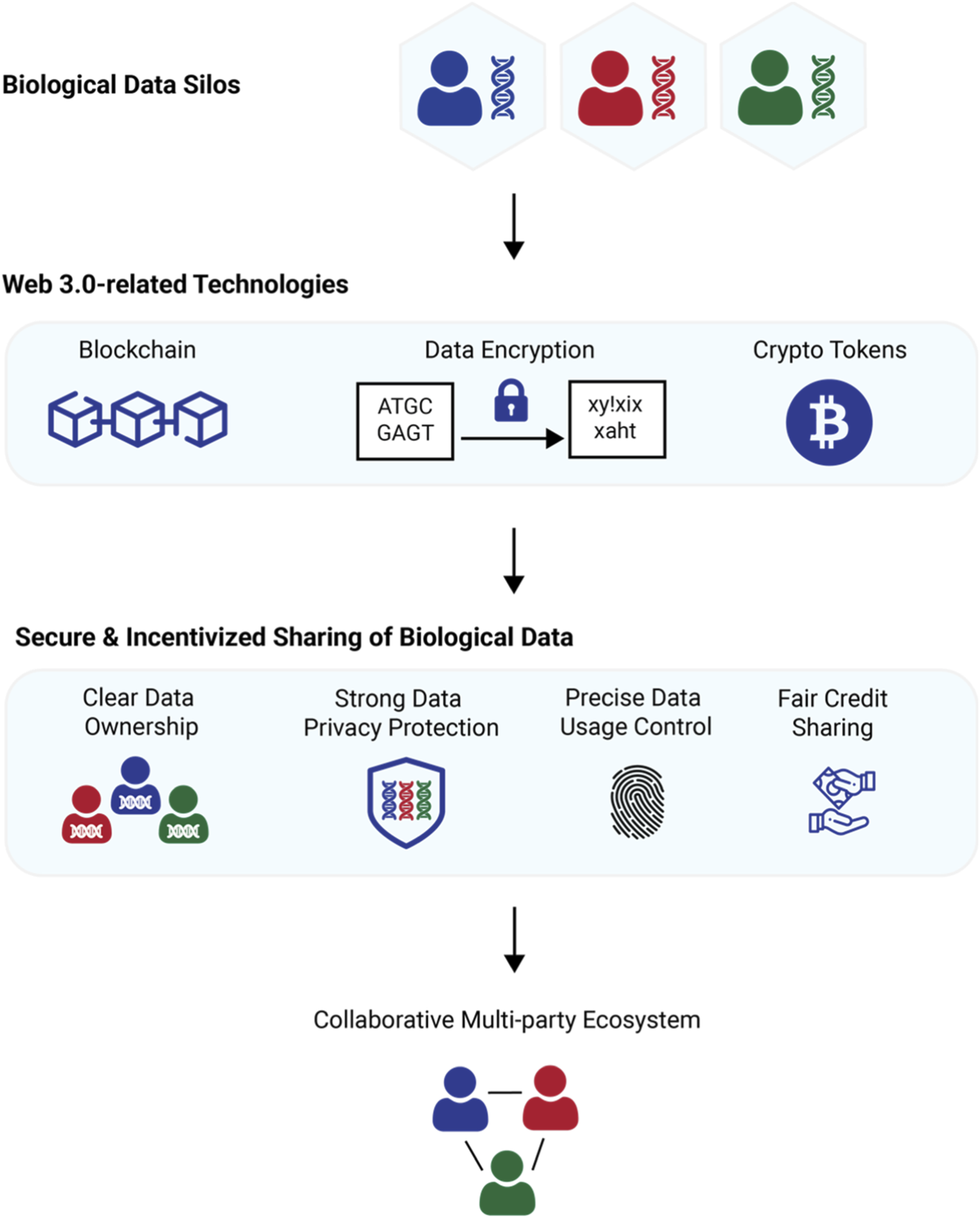
For most new data labeling pipelines, Solana’s micropayment architecture provides a more efficient foundation. ERC-20 remains a strong choice if your project requires deep integration with established Ethereum-based identity or governance systems. Evaluate your expected annotation volume before committing to a standard.
Design the incentive structure
Build a Token-Incentivized Data Labeling Pipeline works best as a clear sequence: define the constraint, compare the realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative. After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.

Integrate the labeling platform
Connecting a decentralized labeling platform to your AI training pipeline requires bridging two distinct systems: the smart contract layer handling token incentives and the data ingestion layer feeding your model. The goal is to ensure that labeled data flows automatically into your training environment while annotations are verified and rewarded on-chain. This integration relies on API endpoints and smart contract interactions to maintain data integrity and token distribution.
1. Configure smart contract interfaces
Start by integrating your pipeline’s backend with the platform’s smart contracts. You need to establish a connection to the ERC-20 token contract to handle incentive payouts and the labeling task contract to submit and retrieve annotation results. Use official SDKs or direct Web3.js/Ethers.js calls to interact with these contracts. Ensure your backend can sign transactions securely using a service account or hardware wallet to automate task creation and reward distribution without manual intervention.
2. Establish data ingestion endpoints
Set up secure API endpoints to receive labeled data from the decentralized network. The platform should push completed, verified annotations to your pipeline’s storage system (such as AWS S3 or IPFS) via webhooks or polling mechanisms. Implement validation logic to check that the data format matches your model’s requirements before it enters the training dataset. This step ensures that only high-quality, token-incentivized data is consumed by your AI models, reducing noise and improving training efficiency.
3. Implement token reward automation
Automate the distribution of tokens to annotators based on verified work. Your integration should monitor the smart contract for task completion events and trigger reward transfers accordingly. Use a reliable oracle or on-chain verification mechanism to confirm that the labeled data meets quality standards before releasing funds. This automation creates a trustless environment where annotators are compensated fairly and promptly, encouraging consistent participation and high-quality output for your data labeling needs.
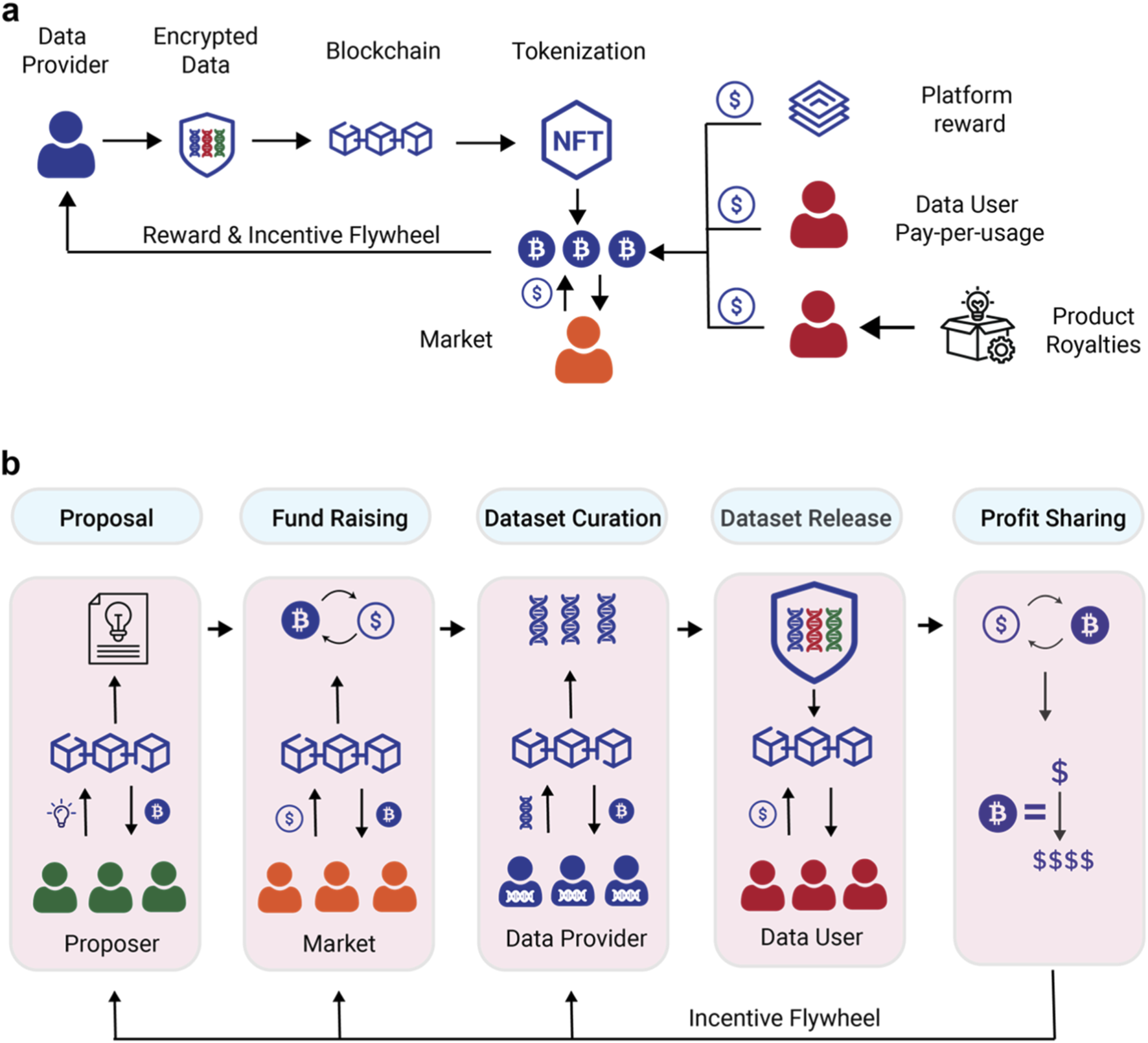
Integrate your backend with the platform’s ERC-20 and task contracts using Web3.js or Ethers.js. Set up secure transaction signing for automated task creation and reward distribution, ensuring your pipeline can interact with the blockchain without exposing private keys.
Configure API endpoints and webhooks to receive verified annotations from the decentralized network. Implement validation checks to ensure incoming data matches your model’s format requirements before it is stored in your training dataset, maintaining data quality and consistency.
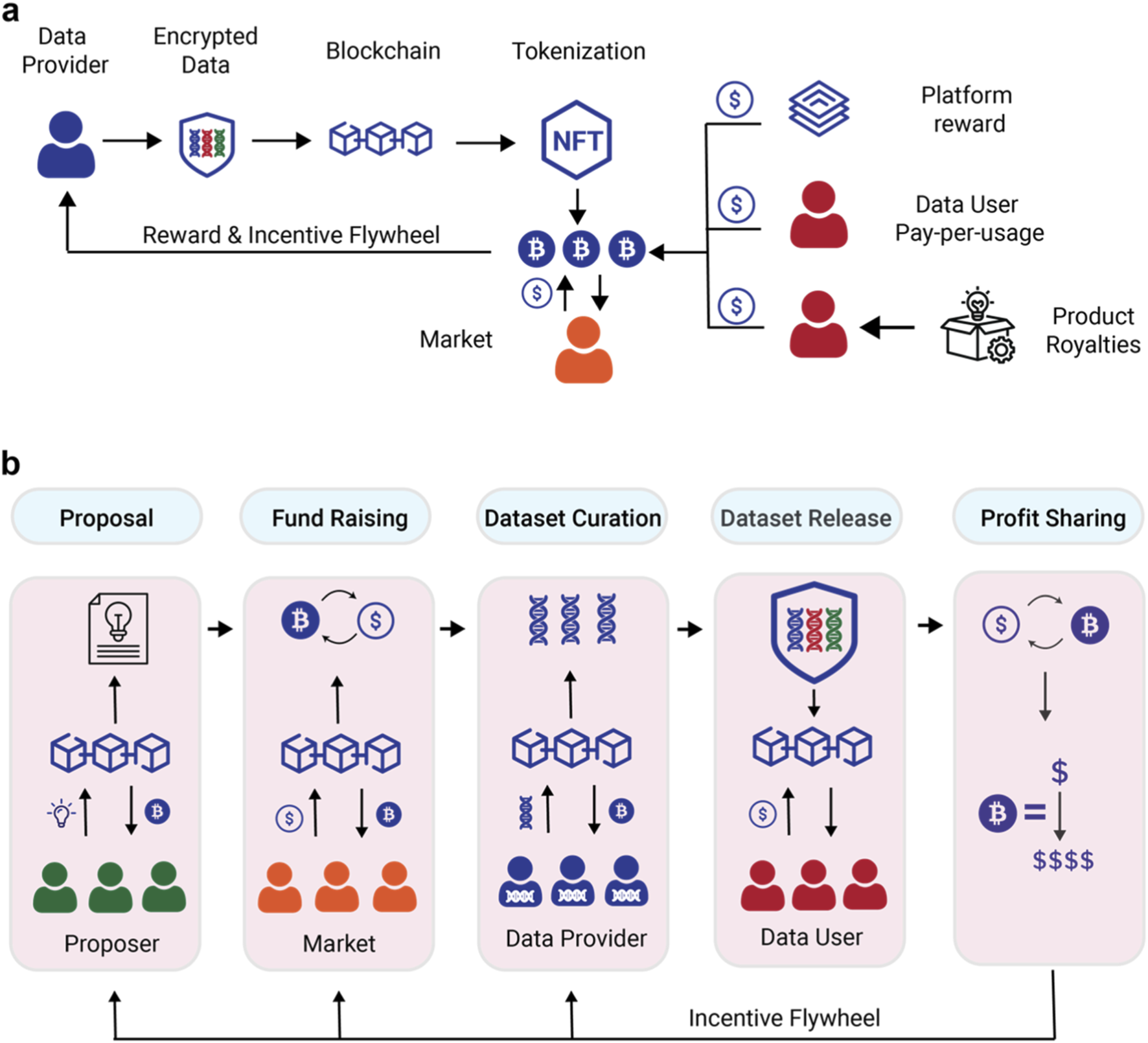
Build automation to monitor on-chain task completion events and trigger token payouts to annotators. Use verification mechanisms to confirm data quality before releasing funds, creating a trustless system that incentivizes high-quality contributions and ensures fair compensation.
Verify data quality and accuracy
Token incentives attract volume, but volume does not equal precision. Without rigorous verification, your model trains on noise. You must implement a multi-layered verification strategy that combines automated consensus with expert oversight to ensure the training data is reliable.
Consensus Mechanisms
Require multiple independent labelers to annotate the same data point. Only accept the label if a majority agrees, or if the labels fall within a defined confidence threshold. This approach filters out random errors and malicious spam, ensuring that the labeled data reflects a stable ground truth rather than individual bias or low-effort work.
Expert Review
Deploy a small team of domain experts to audit a random sample of the consensus-driven data. Experts verify edge cases and complex annotations that automated consensus might miss. This step is critical for high-stakes applications where a single mislabeled image or text snippet can degrade model performance significantly.
Reputation Audits
Track the accuracy history of each labeler. Assign reputation scores based on how often their labels align with expert reviews and consensus outcomes. Labelers with consistent high scores receive priority access to higher-value tasks and better token rewards, while low-performing contributors are flagged for additional training or removed from the pipeline.
- Consensus Thresholds: Set minimum agreement rates (e.g., 3 out of 5 labelers) before accepting a label.
- Expert Sampling: Audit at least 5-10% of all labeled data points weekly.
- Reputation Scoring: Update labeler scores in real-time based on verification outcomes.
-
Define consensus thresholds for each data type
-
Implement automated consensus checking scripts
-
Schedule weekly expert review audits
-
Establish a reputation scoring algorithm for labelers
-
Monitor labeler performance metrics for anomalies
This structured approach ensures that the token-incentivized pipeline produces high-fidelity data. By balancing automated consensus with human expertise and reputation tracking, you create a robust system that rewards accuracy and minimizes the risk of poisoned training sets.
Common questions about token incentives
Is data labeling a viable career?
Yes, data annotation jobs are legitimate and essential. The work of humans-in-the-loop remains critical to the growth of AI and machine learning. Large tech companies, research organizations, and startups rely on annotators to provide high-quality labeled data to train their models. While token incentives add a new layer of motivation, the core value lies in the accuracy of the human judgment provided.
How does data labeling work?
Data labeling annotates raw data with meaningful labels, providing context and categorization for machine learning (ML) models to understand. These labels serve as essential guides for ML models, enabling them to interpret data effectively. In a token-incentivized pipeline, you perform these labeling tasks, and smart contracts verify your output before distributing rewards.
What is the incentive mechanism of Blockchain?
A blockchain incentive mechanism is a means of providing network users an award for activities within the network. Typically used as a system to reward successful publishing of blocks, these mechanisms can also reward specific contributions like data annotation. In this context, tokens are issued as proof of work, creating a transparent and automated payment system for your labeling efforts.
No comments yet. Be the first to share your thoughts!