Define the labeling task scope
Before configuring any token rewards, you must explicitly define the data types and annotation standards for the labeling task. Token-incentivized workflows rely on clear, measurable outputs to function effectively. If the scope is vague, annotators cannot align their efforts, and the incentive mechanism fails to drive quality.
Start by categorizing the data. Is the task image classification, natural language processing, or audio transcription? Each data type requires different annotation tools and quality assurance protocols. For instance, bounding box annotation for object detection demands precise coordinate standards, while sentiment analysis requires nuanced linguistic guidelines.
Next, establish the annotation schema. This document serves as the single source of truth for every annotator. It should include:
- Label definitions: Clear descriptions of each class or tag.
- Edge case rules: How to handle ambiguous or low-quality data.
- Quality thresholds: The minimum accuracy required to unlock rewards.
Research indicates that decentralized platforms using ERC-20 tokens for data labeling can create trustless environments for developers and researchers (IEEE, 2024). However, this trustlessness only works if the underlying task is well-defined. Without a rigid scope, the token economy becomes a tool for gaming the system rather than improving data quality.
Note: Avoid broad categories like "general data." Specificity prevents scope creep and ensures that your token rewards are calibrated to the actual complexity of the work.
Finally, map the complexity of the task to the reward structure. Simple, repetitive tasks should yield smaller, frequent token payouts. Complex, subjective labeling requires higher stakes and potentially multi-stage verification. This alignment ensures that the incentive matches the cognitive load, attracting the right annotators for the job.
Select the token incentive model
Choosing between fixed ERC-20 rewards and dynamic quality-based payouts determines whether your dataset prioritizes speed or accuracy. The decision hinges on the trade-off between predictable operational costs and the need for high-fidelity annotations.
Fixed ERC-20 Rewards
Fixed rewards distribute a set amount of tokens per completed task, regardless of the labeler's historical performance. This model simplifies budgeting and encourages rapid data collection, making it suitable for high-volume, low-complexity labeling tasks. However, it does not inherently penalize low-quality work, potentially flooding your dataset with noise.
Dynamic Quality-Based Payouts
Dynamic models adjust payouts based on real-time quality scores, consensus mechanisms, or reviewer feedback. This approach aligns incentives with data accuracy, rewarding labelers who consistently produce high-quality annotations. While it increases administrative complexity and may slow down initial throughput, it significantly reduces the cost of post-hoc data cleaning.
Comparison of Reward Structures
The following table compares the operational characteristics of both models to help you select the appropriate structure for your workflow.
| Feature | Fixed ERC-20 | Quality-Based |
|---|---|---|
| Cost Predictability | High | Variable |
| Data Accuracy | Low to Medium | High |
| Implementation Complexity | Low | High |
| Best Use Case | High-volume, simple tasks | Complex, nuanced annotations |
Implementation Recommendation
For most production-grade datasets, a hybrid approach often yields the best results. Start with fixed rewards to build initial volume, then layer in dynamic bonuses for tasks that require higher precision. This strategy balances the need for scale with the necessity of accuracy, ensuring your model is trained on reliable data without breaking the budget.
Integrate smart contract automation
Deploying smart contracts transforms the token-incentivized data labeling workflow from a manual accounting exercise into an automated, trustless system. By embedding the distribution logic directly into the blockchain, you eliminate the overhead of manual payouts and reduce the risk of human error or dispute.
The following steps outline the technical sequence for deploying these contracts, ensuring that tokens are distributed only after data verification.
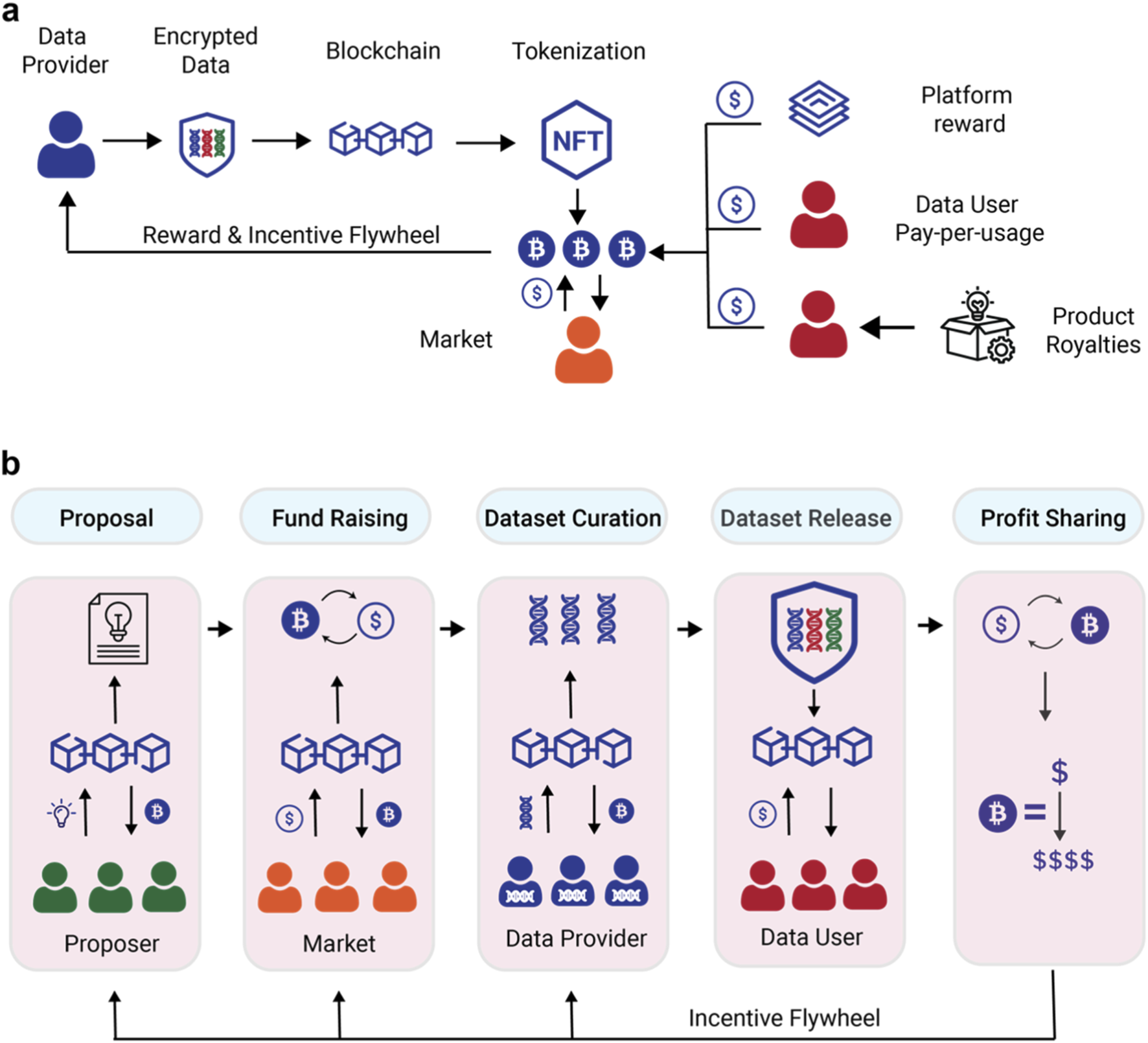
Begin by selecting or deploying an ERC-20 token contract. This standard ensures compatibility with most wallets and exchanges. Research such as the IEEE paper on Decentralized Data Labeling Platforms (DDLP) highlights how ERC-20 tokens provide a trustless environment for developers and researchers, allowing for standardized, predictable token interactions without custom protocol overhead.

Write the smart contract functions that handle the actual payout. These functions must include strict conditions: the labeler’s identity must be verified, the data quality score must meet the predefined threshold, and the transaction must be confirmed on-chain. This logic ensures that tokens are only released when the work is genuinely accepted, preventing fraud and ensuring fair compensation.
Connect your smart contract to an off-chain data source or oracle. Since blockchains cannot natively verify the quality of image or text labels, you need an oracle to feed verification results (e.g., "approved" or "rejected") into the contract. This step bridges the gap between off-chain human labor and on-chain automation.

Before going live, deploy the contract to a testnet like Sepolia or Goerli. Use test tokens to simulate the full workflow: submit a label, trigger the verification, and confirm the token transfer. This phase is critical for identifying bugs in the distribution logic or gas limit issues before real funds are at risk.

Once testing is complete, deploy the contract to the mainnet. Verify the source code on a block explorer like Etherscan to build transparency and trust with your labelers. Finally, integrate the contract address into your frontend application so users can initiate labeling tasks and view their pending rewards in real time.
This automation creates a self-sustaining ecosystem where incentives are directly tied to verified output, reducing administrative costs and increasing the reliability of your data labeling pipeline.
Implement quality control mechanisms
Token incentives alone can attract bad actors. Without guardrails, Sybil attacks and low-effort submissions degrade the dataset, rendering the AI training data useless. You must build verification layers that make cheating more expensive than honest work.
Consensus-based verification
Require multiple annotators to label the same item. The system only accepts the result if a threshold of independent workers agree. This approach neutralizes individual bias or malicious intent. For high-stakes models, aim for a minimum of three independent labels per item.
Reputation staking
Implement a reputation system where annotators stake tokens to participate. Poor quality or inconsistent labeling results in slashing (loss of staked tokens). This creates a financial disincentive for spam. High-reputation users earn higher payout rates, rewarding consistency over time.
Random audits
Introduce expert review for a random subset of labeled data. Use these audits to calculate a quality score for each annotator. Adjust their payout rates or reputation levels based on this score. This ensures continuous alignment with ground truth.
Warning: Without robust quality control, token incentives can lead to spam labeling and degraded model performance.
Bot detection
Monitor for patterns indicative of automated scripts. Flag accounts that complete tasks too quickly or submit identical labels across diverse inputs. Require CAPTCHA challenges or human verification steps for suspicious activity. This prevents Sybil attacks at the entry point.
Feedback loops
Create a transparent dispute resolution process. Allow annotators to challenge low-quality labels or unfair slashing. Use these disputes to refine your quality thresholds. This builds trust within the labeling community and reduces churn.
Launch and monitor the annotation pipeline
Go live by running a controlled pilot before full deployment. Start with a small batch of tasks to validate the token distribution logic and verify that labelers can claim rewards without friction. This initial phase acts as a stress test for your smart contract and user interface, catching bugs before they scale.
Once the pilot stabilizes, shift to continuous monitoring. Track three core metrics to ensure sustainable scaling: token burn rates to prevent inflation, labeler retention to maintain workforce stability, and data quality scores to verify annotation accuracy. A decentralized approach, powered by blockchain and crypto tokens, can democratize data labeling, but only if the incentive structure remains balanced over time [src-serp-4].
Use a pre-launch checklist to guarantee nothing is missed during the rollout.
-
Verify smart contract deployment on testnet
-
Run pilot with 10-20 internal labelers
-
Confirm token reward claims process
-
Set up dashboards for burn rate and quality metrics
-
Establish a feedback loop for low-quality annotations
Frequently asked questions about token incentives
Token incentives transform data labeling from a transactional task into a trustless, gamified workflow. By leveraging blockchain mechanics, platforms can reward accuracy and volume simultaneously, addressing the high cost and inconsistency often associated with traditional labeling.
No comments yet. Be the first to share your thoughts!