Define the reward tokenomics
Start by selecting the ERC-20 standard for your incentive token. While other standards exist, ERC-20 provides the necessary liquidity and compatibility with existing decentralized exchanges (DEXs) and wallets. This standardization allows annotators to easily trade, stake, or hold their rewards without requiring custom smart contract integration.
Next, establish the correlation between data quality and reward magnitude. A flat rate per label creates perverse incentives for speed over accuracy. Instead, implement a tiered structure where higher-quality annotations—verified by consensus mechanisms or expert audits—earn a premium. This ensures the platform maintains high data integrity, which is critical for training reliable AI models.
Finally, model the token supply to prevent hyperinflation. If the reward pool exceeds the demand for labeled data, the token price will collapse, demotivating annotators. Set a fixed emission schedule tied to the volume of verified tasks. This creates a sustainable economic loop where developers pay for quality data, and annotators earn a stable, predictable value for their labor.
Deploy the smart contract infrastructure
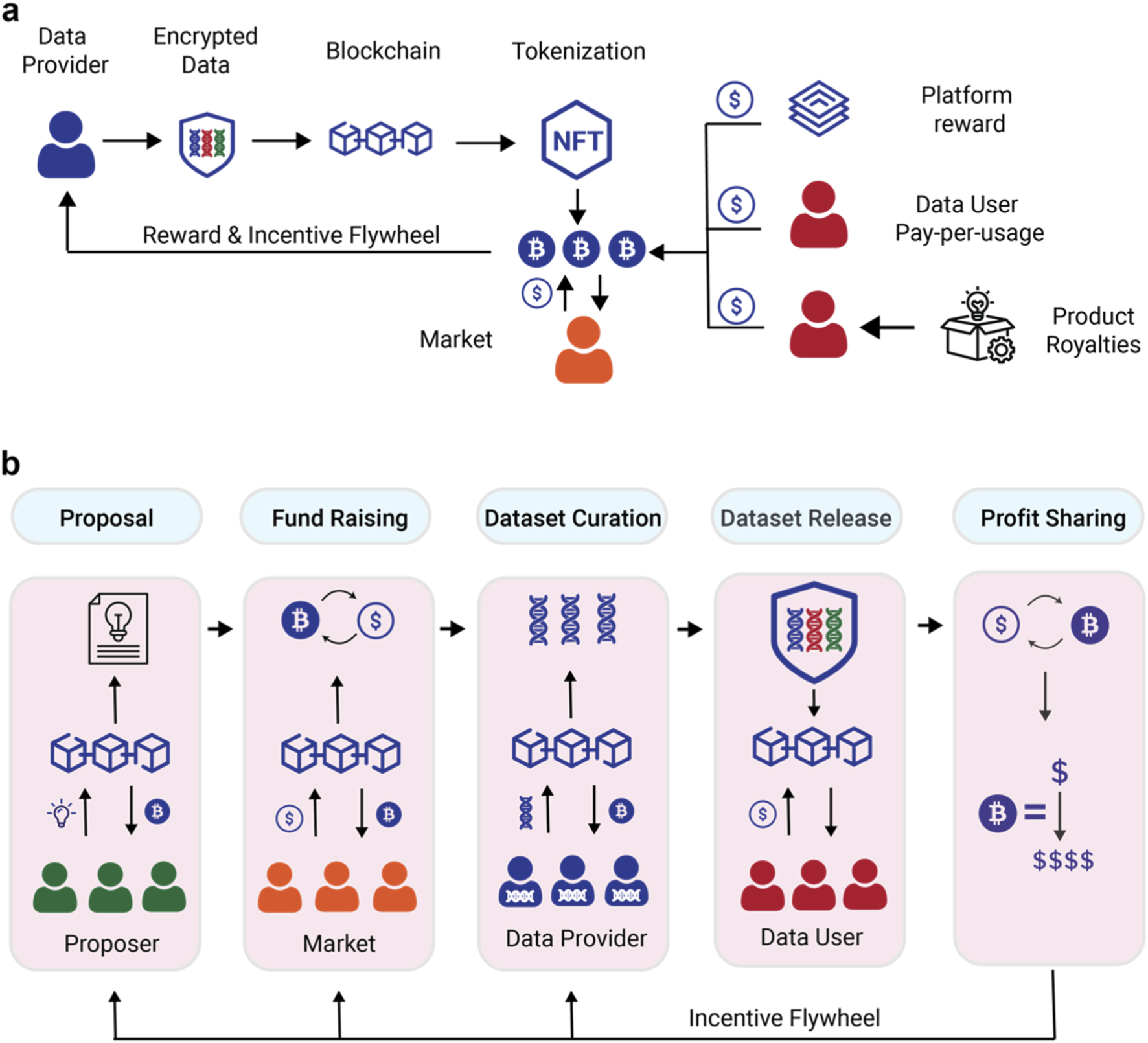
The backbone of a token-incentivized data labeling platform relies on on-chain logic that automates task distribution and reward settlement. By deploying smart contracts, you create a trustless environment where data contributors are compensated directly for accurate annotations, removing the need for centralized intermediaries to hold funds or verify outputs manually. This section outlines the technical sequence for deploying the core contracts that manage these interactions.
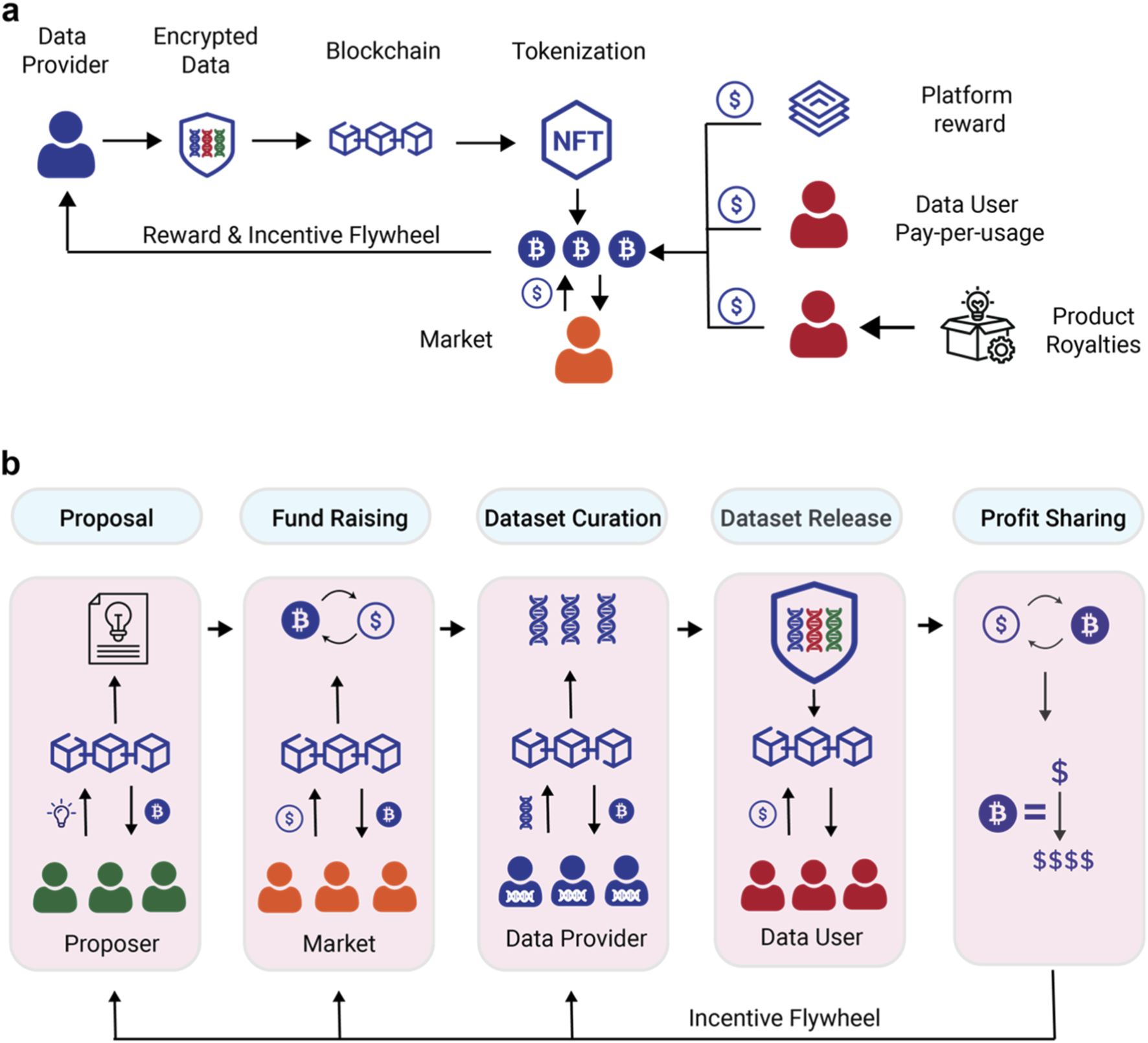
Begin by defining the smart contracts in Solidity. You need at least two core components: a TaskManager contract to handle the creation, assignment, and verification of labeling jobs, and a RewardPool contract to manage the ERC-20 token distribution. The TaskManager should include functions to submit labeling results and trigger verification, while the RewardPool ensures that tokens are only released when a task is marked as complete and accepted. Reference academic models, such as those exploring ERC-20 incentives for decentralized labeling, to ensure your logic aligns with established trustless frameworks.

Before touching mainnet funds, deploy your contracts to a testnet like Sepolia or Goerli. Use a deployment tool like Hardhat or Foundry to automate the process. Fund your deployment account with testnet ETH to cover gas fees. This step allows you to verify that the task creation and reward distribution functions execute correctly without financial risk. It is also the ideal time to test edge cases, such as what happens if an annotator submits invalid data or if the verification threshold is not met.
Transparency is critical for user trust in decentralized platforms. Verify your contract source code on a block explorer like Etherscan or BscScan. This process makes your contract’s ABI and source code publicly readable, allowing developers and users to audit the logic. Verification also enables the block explorer to generate an interactive "Write Contract" tab, which simplifies frontend integration by providing a pre-built interface for calling your contract functions.
Connect your frontend application to the deployed contracts using a library like ethers.js or viem. Implement wallet connection logic (e.g., MetaMask, WalletConnect) so users can sign transactions for task submission and reward claims. Ensure the frontend correctly parses contract events, such as TaskVerified or RewardDistributed, to update the UI in real time. This integration bridges the gap between the user interface and the on-chain infrastructure, completing the deployment cycle.
Implement quality control mechanisms
Preventing low-quality or malicious labeling requires a system that rewards accuracy and penalizes negligence. Instead of relying on a single annotator, you implement consensus-based validation. This means assigning each data task to multiple independent labelers. The system only accepts a label if a predefined threshold of annotators agrees on the output. This approach, often called "crowdsourced verification," significantly reduces the risk of individual error or intentional sabotage.
To enforce this, you can use token staking. Labelers must stake tokens before starting a task. If their output aligns with the consensus, they receive their stake back plus a reward. If their output deviates from the majority, they face "slashing"—a penalty where a portion of their staked tokens is burned or transferred to the protocol. This economic disincentive ensures that labelers have a financial reason to be careful and honest.
The choice between centralized and decentralized quality control impacts both cost and reliability. Centralized systems rely on manual review by experts, which is accurate but expensive and slow. Decentralized systems use on-chain consensus and token staking to automate accuracy checks, offering scalability at a lower marginal cost.
| Model | Validation Method | Cost Structure | Scalability |
|---|---|---|---|
| Centralized | Manual expert review | High per-label | Low |
| Decentralized | On-chain consensus | Low per-label | High |
| Hybrid | Consensus + spot checks | Medium | Medium-High |
This structure creates a self-correcting ecosystem. As noted in industry analyses, token economic models allow projects to incentivize labelers to provide high-quality contributions while effectively addressing the low-quality data problem inherent in traditional labeling pipelines [src-serp-3]. By aligning financial incentives with data integrity, you build a platform that scales without sacrificing accuracy.
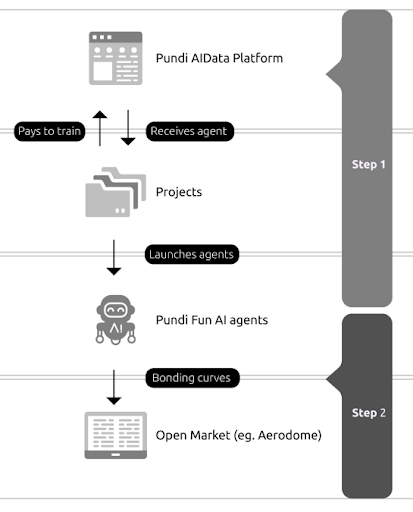
Integrate with AI model pipelines
With labeled data secured on-chain and token rewards distributed, the final step is transferring the dataset to your AI training infrastructure. This phase ensures that the high-quality, verified annotations move seamlessly from the decentralized platform to the model pipeline without corruption or format errors.
1. Standardize Data Formats
AI models require specific input structures, such as JSON, CSV, or Parquet. Your platform should include a built-in converter that transforms the raw labeled data from the blockchain into these standard formats. This step prevents manual preprocessing errors and ensures compatibility with major frameworks like PyTorch or TensorFlow.
2. Verify Data Integrity via Hashes
Before uploading, cross-reference the dataset’s cryptographic hash with the on-chain record. This verification confirms that the data has not been altered since labeling. Any mismatch indicates tampering or transmission errors, allowing you to reject the batch before it contaminates the training set.
3. Upload to Secure Storage
Store the final dataset in a secure, accessible location such as AWS S3, Google Cloud Storage, or IPFS. Use the blockchain to store the access keys or pointers to the data, ensuring that only authorized pipelines can retrieve the verified labels. This creates a transparent audit trail for every data batch used in model training.
4. Trigger Model Retraining
Once the data is uploaded and verified, trigger an automated pipeline to begin model retraining. This can be done via API calls to your MLOps platform. The system should log the start time, dataset version, and on-chain transaction hash, creating a complete record of the model’s evolution.
Convert raw labeled data into JSON, CSV, or Parquet formats compatible with PyTorch or TensorFlow. This prevents manual preprocessing errors and ensures immediate compatibility with major AI frameworks.
Cross-reference the dataset’s cryptographic hash with the on-chain record. This confirms the data has not been altered since labeling, allowing you to reject any batch that shows signs of tampering or transmission errors.
Store the final dataset in AWS S3, Google Cloud Storage, or IPFS. Use the blockchain to store access keys or pointers, ensuring only authorized pipelines can retrieve the verified labels for training.
Trigger an automated pipeline via API to begin model retraining. Log the start time, dataset version, and on-chain transaction hash to create a complete audit trail of the model’s evolution.
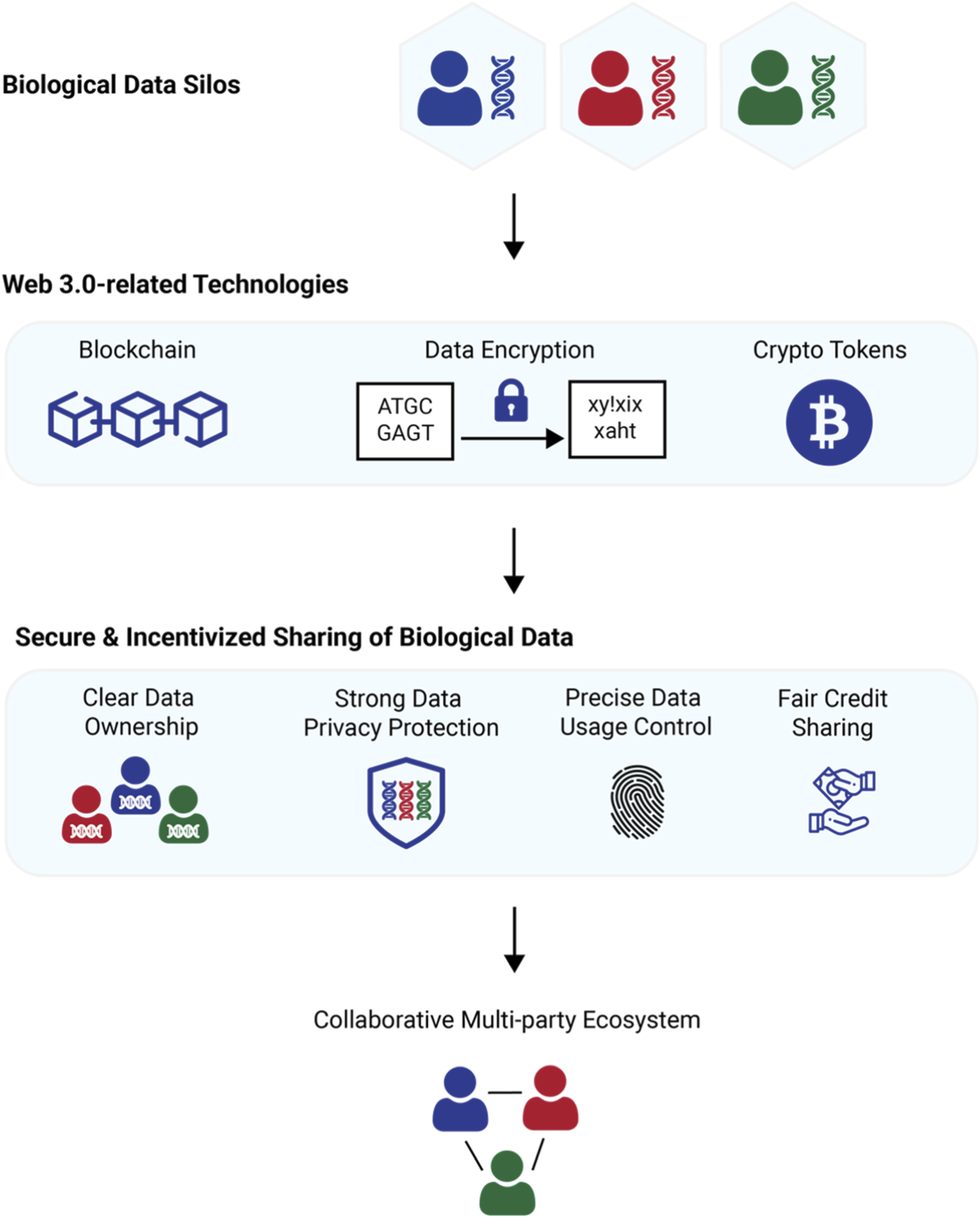
A decentralized approach, powered by blockchain and crypto tokens, can democratize data labeling, incentivizing contributions from a broader community. By integrating this verified data directly into your AI pipelines, you ensure that the benefits of AI development are shared fairly while maintaining high-quality training standards.
Common questions about decentralized labeling
Building a token-incentivized data labeling platform requires addressing specific concerns about economic stability, data privacy, and the practicality of crowdsourced work in high-stakes AI development.
How do you handle token volatility for labelers?
Token incentives introduce market risk that can deter consistent participation. Platforms typically use stablecoins or algorithmic mechanisms to decouple reward value from crypto market swings, ensuring labelers receive predictable compensation for their time. This stability is essential for maintaining a reliable workforce, as noted in research on ERC-20 token applications for data labeling [[src-serp-1]].
Is my training data secure and private?
Data privacy is maintained through cryptographic techniques and access controls inherent to blockchain architecture. Sensitive datasets are often encrypted, and labelers interact only with anonymized or masked data segments necessary for their specific tasks. This approach minimizes exposure risks while allowing for transparent audit trails of data usage, a key advantage highlighted in blockchain-driven AI annotation studies [[src-serp-3]].
Can crowdsourced labeling match expert quality?
Crowdsourced labeling can achieve high accuracy when combined with consensus mechanisms and expert validation layers. By requiring multiple independent labels for the same data point and aggregating results, platforms can filter out noise and errors. This method leverages the "wisdom of the crowd" while retaining expert oversight for final quality assurance, making it viable for complex AI training needs [[src-serp-1]].
No comments yet. Be the first to share your thoughts!