Get token-incentivized data labeling right
Before deploying a tokenized labeling pipeline, align your technical stack with the economic incentives you plan to offer. The system relies on smart contracts to distribute rewards, so the infrastructure must support both secure data storage and transparent payment logic. Using Ethereum smart contracts combined with decentralized storage like IPFS ensures that labeled data remains immutable and accessible without a central point of failure. This trustless architecture allows developers to verify data quality without relying on a single vendor’s oversight.
Next, define a clear tokenomics model that balances annotator effort with project sustainability. Incentive layers typically reward participants for maintaining network integrity and honest behavior. For example, projects like Deano use specific tokens to reward annotators for accurate data labeling, creating a win-win dynamic where vendors get high-quality datasets and contributors earn fair compensation. If your reward structure is too low, you will attract low-effort submissions; if it is too high, you risk inflation or unsustainable burn rates.
Finally, establish a quality assurance protocol that leverages consensus mechanisms. Since you are paying per token, you need a way to detect and filter out malicious or lazy labeling. Implement a multi-annotator consensus model where multiple independent labelers tag the same data point. The system can then compare outputs, flag discrepancies for review, and only approve labels that meet a predefined accuracy threshold. This ensures that your AI training data is robust, even when generated by a decentralized, token-incentivized workforce.
How to implement token-incentivized data labeling
Implementing a token-incentivized data labeling system requires aligning smart contract logic with human annotation workflows. The goal is to create a trustless environment where data quality is verified automatically and rewarded instantly. This process moves beyond traditional crowdsourcing by using blockchain mechanics to ensure annotators are paid fairly for accurate work, while AI developers receive clean, verified datasets.
The following steps outline the end-to-end workflow for setting up this infrastructure, from token design to final dataset integration.
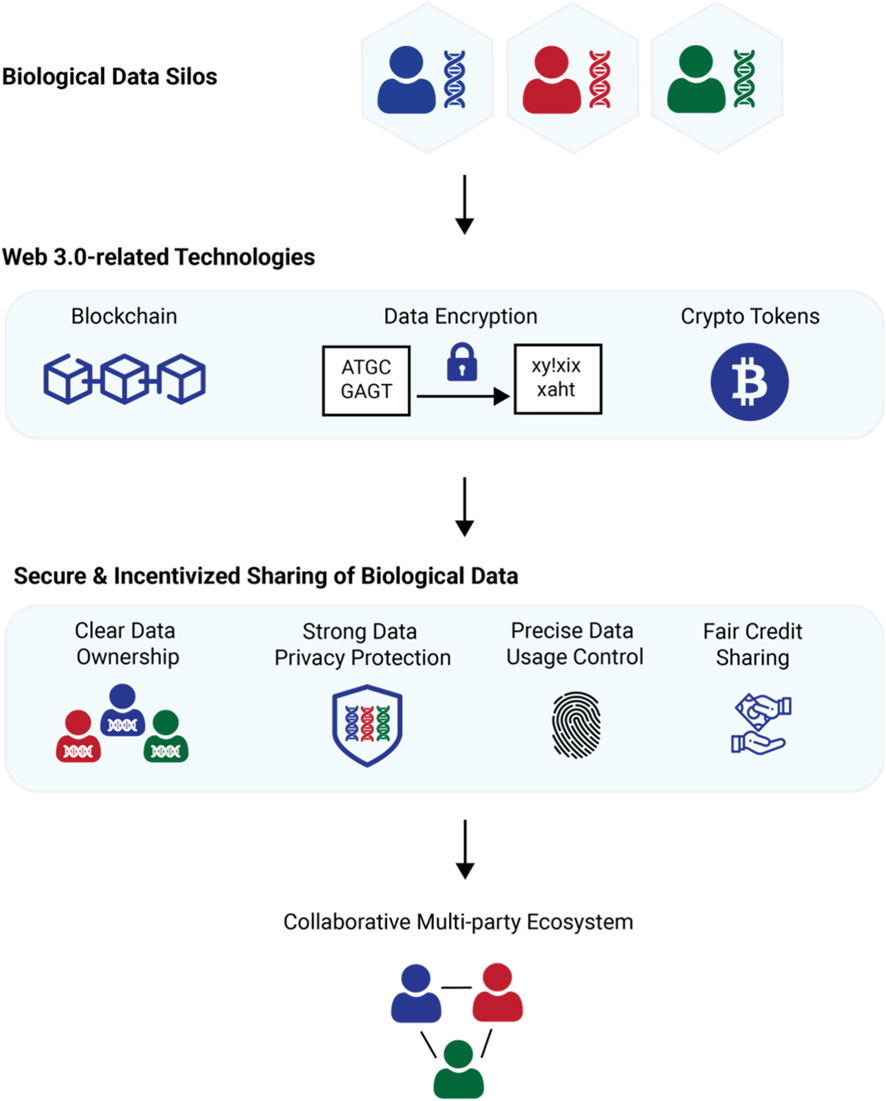
Begin by defining the economic model. You need to determine the token standard (typically ERC-20) and the reward rate per verified label. The incentive layer must reward participants for maintaining network integrity and honest behavior. Set clear metrics for what constitutes "accurate" labeling, such as consensus thresholds where multiple annotators must agree on a tag before the token reward is released. This prevents spam and ensures data quality from the start.
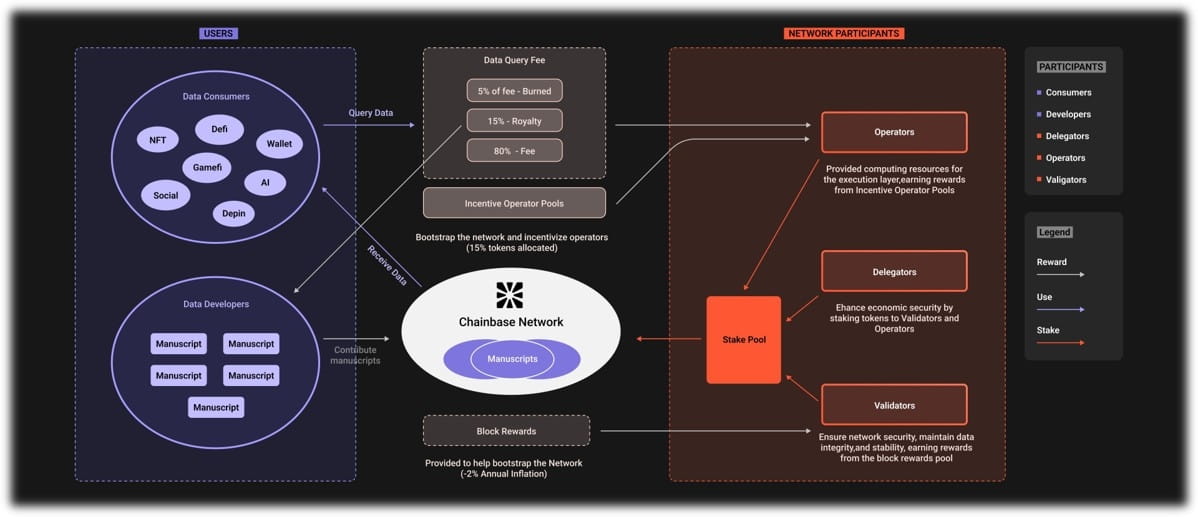
Code the logic that governs the labeling process. The smart contract should handle task distribution, track annotator submissions, and manage the reward pool. It must include a dispute resolution mechanism or a reputation system where high-performing annotators get priority access to higher-paying tasks. This layer acts as the automated manager, removing the need for a central platform to mediate payments or resolve quality disputes manually.
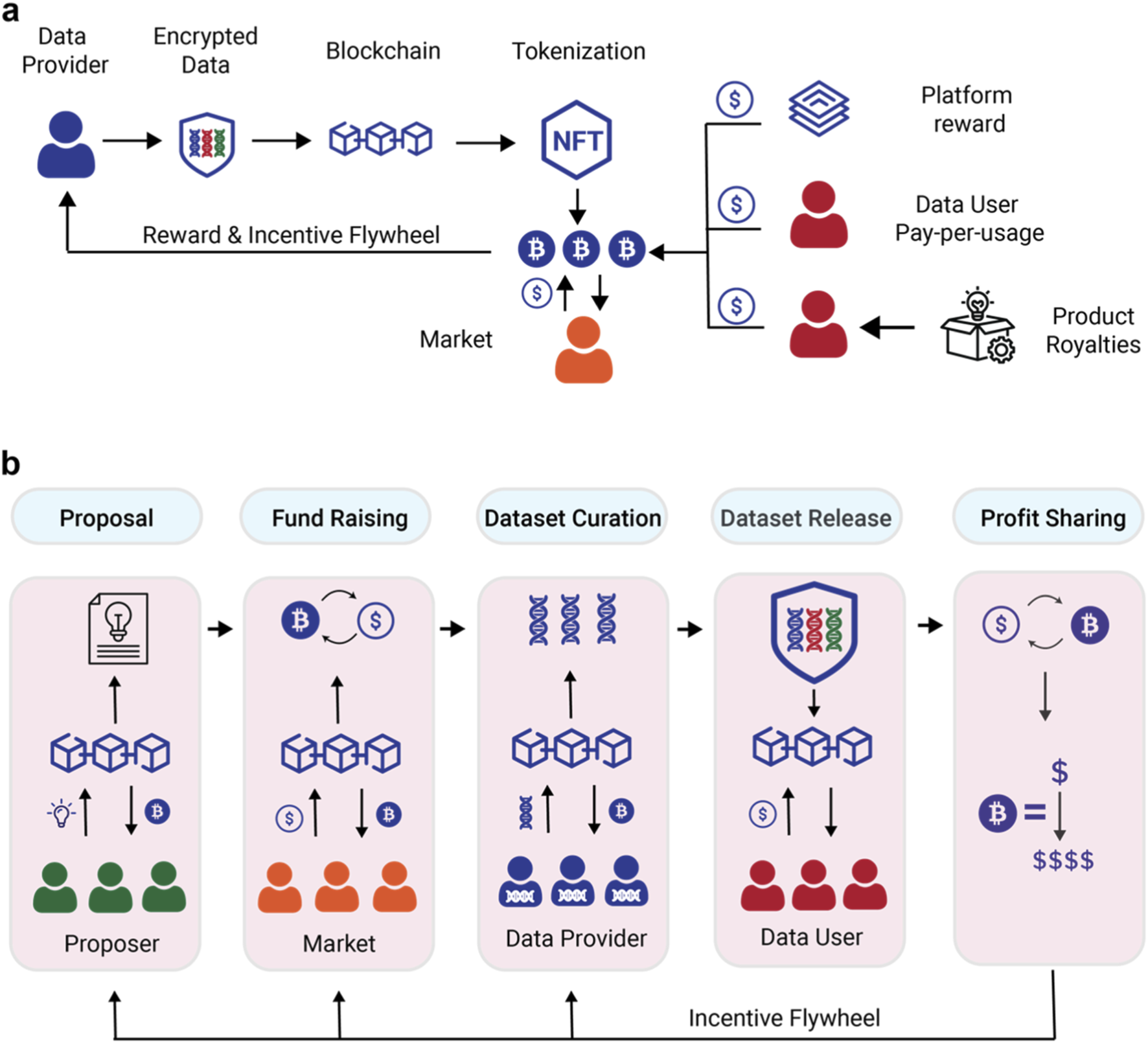
Create a user-friendly frontend where annotators can view tasks and submit labels. This interface must connect to the user’s crypto wallet to verify identity and receive payments. The UI should provide clear instructions for each data point, whether it’s image tagging, text classification, or audio transcription. Transparency is key; annotators should see their real-time earnings and reputation score to stay motivated and engaged with the platform.
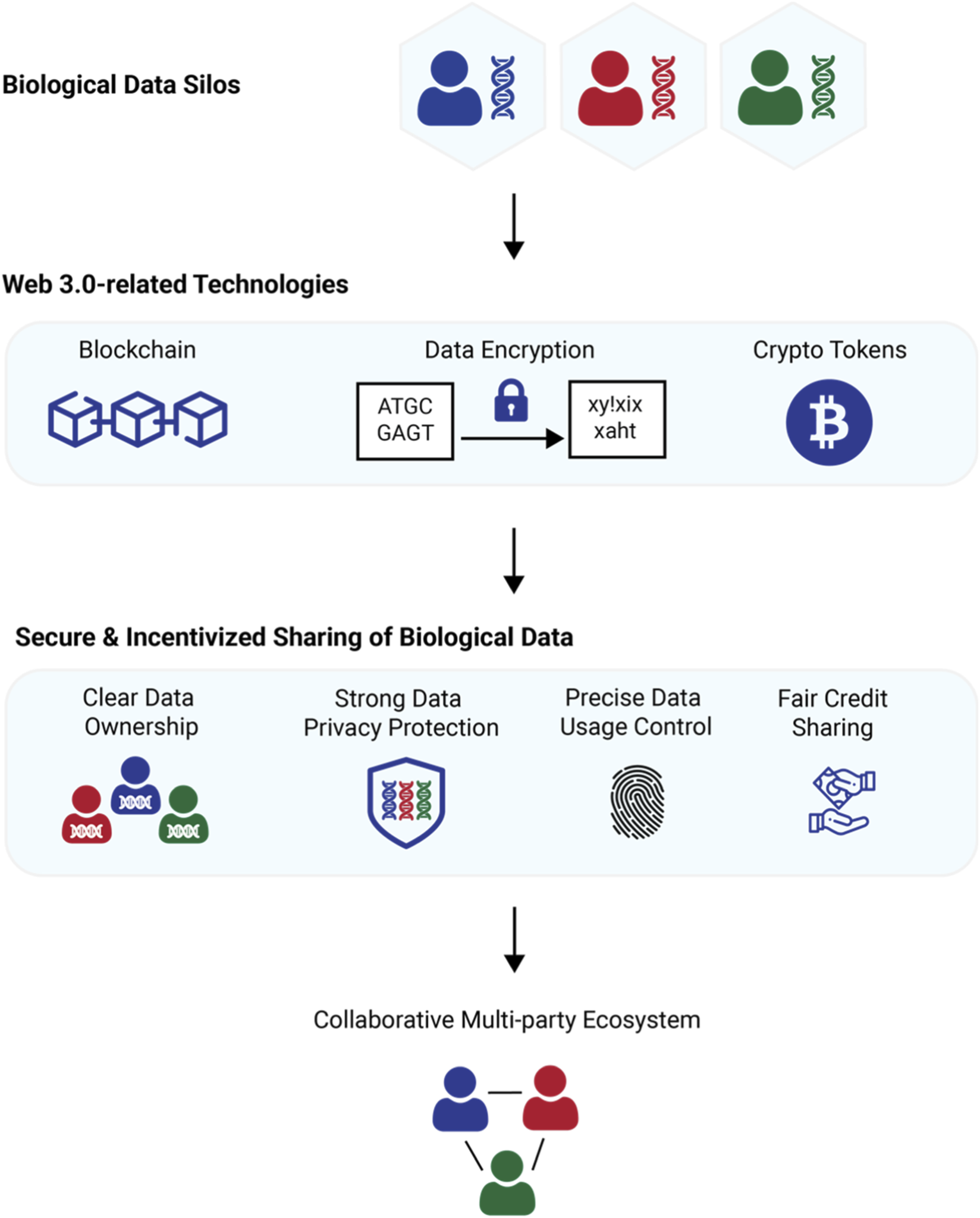
Store the raw data and resulting labels on a decentralized network like IPFS. This ensures that the dataset is immutable and resistant to censorship or tampering. When an annotator submits a label, the hash of the data and the label itself is recorded on-chain, while the actual file content is stored off-chain. This reduces costs and improves scalability, allowing the system to handle large-scale AI training datasets without bloating the blockchain.

Once labeling is complete, run a quality assurance protocol. This might involve cross-referencing labels with known ground truth or using a majority-vote consensus among multiple annotators. After verification, the smart contract automatically distributes tokens to the wallets of the contributors. The verified dataset is then made available to AI developers for training models, completing the cycle from raw data to high-quality AI fuel.
-
Define token reward rates and consensus thresholds
-
Deploy ERC-20 smart contract with verification logic
-
Develop frontend interface with wallet integration
-
Set up IPFS gateway for decentralized storage
-
Implement automated reward distribution mechanism
Fix common mistakes
Token-incentivized data labeling promises scalable, high-quality training data, but the system is fragile. When the reward mechanism is misaligned with data quality, you get volume without value. The following errors are the most common causes of poor model outcomes in 2026.
Misaligned Reward Structures
Paying per annotation rather than per accuracy encourages speed over precision. If annotators are rewarded for volume, they will rush through ambiguous cases, introducing noise into the training set. This creates a "garbage in, garbage out" scenario where the model learns incorrect patterns.
Fix: Tie token rewards to verified accuracy. Use consensus mechanisms where multiple annotators label the same data, or implement post-labeling audits by expert reviewers. Only pay tokens when the label is confirmed correct.
Poor Quality Control (QC)
Without rigorous QC, low-quality labels accumulate. A single bad label can skew a model's decision boundary, especially in edge cases. Many projects skip intermediate checks, assuming that the incentive layer will self-correct. It won't.
Fix: Implement multi-stage QC. Use a tiered system where junior annotators submit work, and senior annotators or AI-assisted tools verify a sample. Reject low-quality batches immediately and provide feedback to the annotator.
Inadequate Annotator Training
Annotators are not always domain experts. Without clear guidelines, they interpret tasks differently, leading to inconsistent labels. This variability makes it difficult to train a robust model, as the data lacks uniformity.
Fix: Provide comprehensive training materials and examples. Use a "gold standard" dataset for calibration. Regularly update guidelines as edge cases are discovered and ensure annotators can ask questions when uncertain.
Ignoring Data Bias
Incentive structures can inadvertently amplify bias. If certain types of data are more profitable or easier to label, annotators may focus on those, neglecting underrepresented groups. This leads to models that perform well on common cases but fail on diverse inputs.
Fix: Actively monitor the distribution of labeled data. Set quotas for underrepresented categories and adjust incentives to encourage balanced labeling. Regularly audit the dataset for bias and rebalance as needed.
Token-incentivized data labeling: what to check next
What is the incentive layer of the Blockchain?
The incentive layer is the economic engine that rewards participants, such as miners or validators, for maintaining network security and honesty. It uses token distributions to ensure continuous participation. In data labeling, this layer shifts from securing blocks to securing data accuracy. Platforms like DDLP use Ethereum smart contracts to distribute ERC-20 tokens when labelers provide verified annotations, turning data contribution into a tangible, trustless reward system.
How to start data labeling with token incentives?
Start by choosing a decentralized platform that matches your expertise, such as Sapien or Deano. Create a wallet to receive tokens and complete any required identity verification. Begin with small, low-complexity tasks to build your reputation score. As your accuracy rate improves, you unlock higher-paying tasks and better token rewards. This gamified approach replaces fixed hourly wages with performance-based earnings.
Are token rewards stable and reliable?
Token values fluctuate with market conditions, making rewards volatile compared to traditional fiat pay. Some platforms mitigate this by pegging rewards to stablecoins or offering immediate fiat conversion options. For example, Deano uses DAN tokens, which may vary in value. Always check the platform’s payout structure and withdrawal policies before committing significant time. The potential for higher earnings comes with the risk of crypto market instability.
How does blockchain ensure data quality?
Blockchain creates an immutable record of every labeling decision, allowing for transparent audit trails. Smart contracts automatically verify annotations against consensus rules before releasing payments. If a labeler’s work deviates from the majority consensus or fails quality checks, the system withholds rewards. This automated enforcement reduces fraud and ensures that AI models receive high-quality, verified training data without manual oversight.
No comments yet. Be the first to share your thoughts!