Get token-incentivized data labeling right
Before launching a token-incentivized data labeling project, you must define the economic and technical rules that govern quality. Unlike traditional crowdsourcing, blockchain-based systems rely on smart contracts to automate rewards and penalties, meaning your initial configuration dictates the long-term behavior of your annotators.
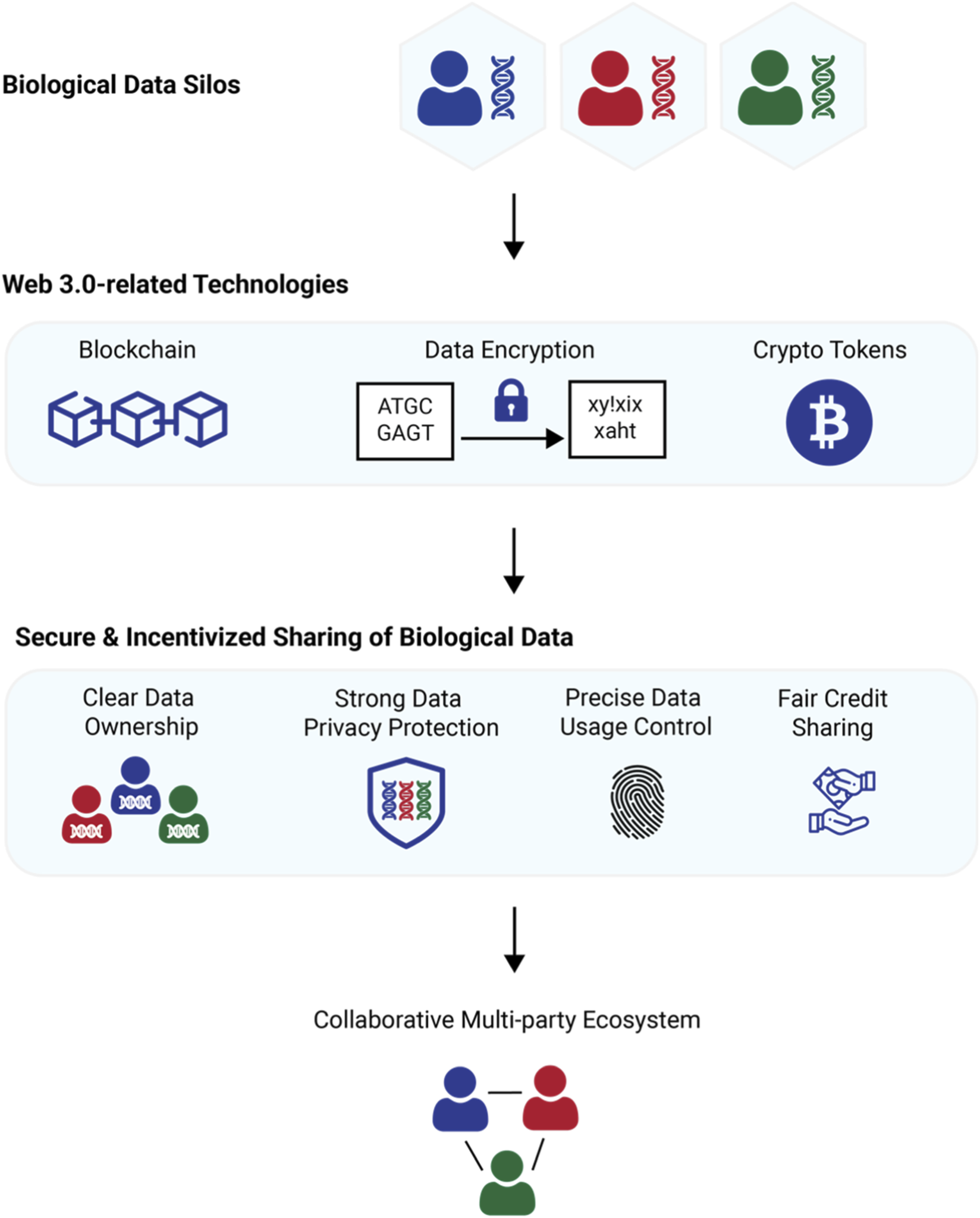
Start by selecting a token standard that aligns with your infrastructure. ERC-20 tokens are the most common choice for simple reward distributions, as seen in projects like DDLP, which uses Ethereum smart contracts to manage trustless interactions between developers and researchers. Ensure your labeling platform can integrate with decentralized storage solutions like IPFS to guarantee data integrity without exposing sensitive training sets to centralized points of failure.
Next, establish clear incentive mechanisms. A robust crypto incentive model uses rewards for high-quality work and penalties for errors or malicious submissions. This creates a win-win dynamic where annotators are motivated to maintain accuracy to maximize their token earnings. Define these rules explicitly in your smart contract logic before inviting any contributors.
Finally, audit your tokenomics to prevent inflation or exploitation. If the reward rate is too high, you may attract low-quality "sybil" attacks from bots. If it is too low, you will fail to retain skilled human annotators. Balance these factors by testing your contract with a small pilot group to verify that the reward structure actually drives the accuracy you need for your AI training data.
Set up the token-incentivized data labeling workflow
Token-incentivized data labeling turns crowd workers into paid annotators by rewarding them with crypto tokens for high-quality work. This model reduces bias and scales training data faster than traditional paid platforms. The system relies on smart contracts to automate payments and verify accuracy.
1. Deploy the smart contract
Start by deploying an ERC-20 token contract on your chosen blockchain, such as Ethereum. This contract holds the reward pool and defines the rules for distribution. Use IPFS for decentralized storage of labeling instructions to ensure they cannot be altered mid-task. The contract must include functions to mint tokens for workers and burn them upon task completion to prevent inflation.
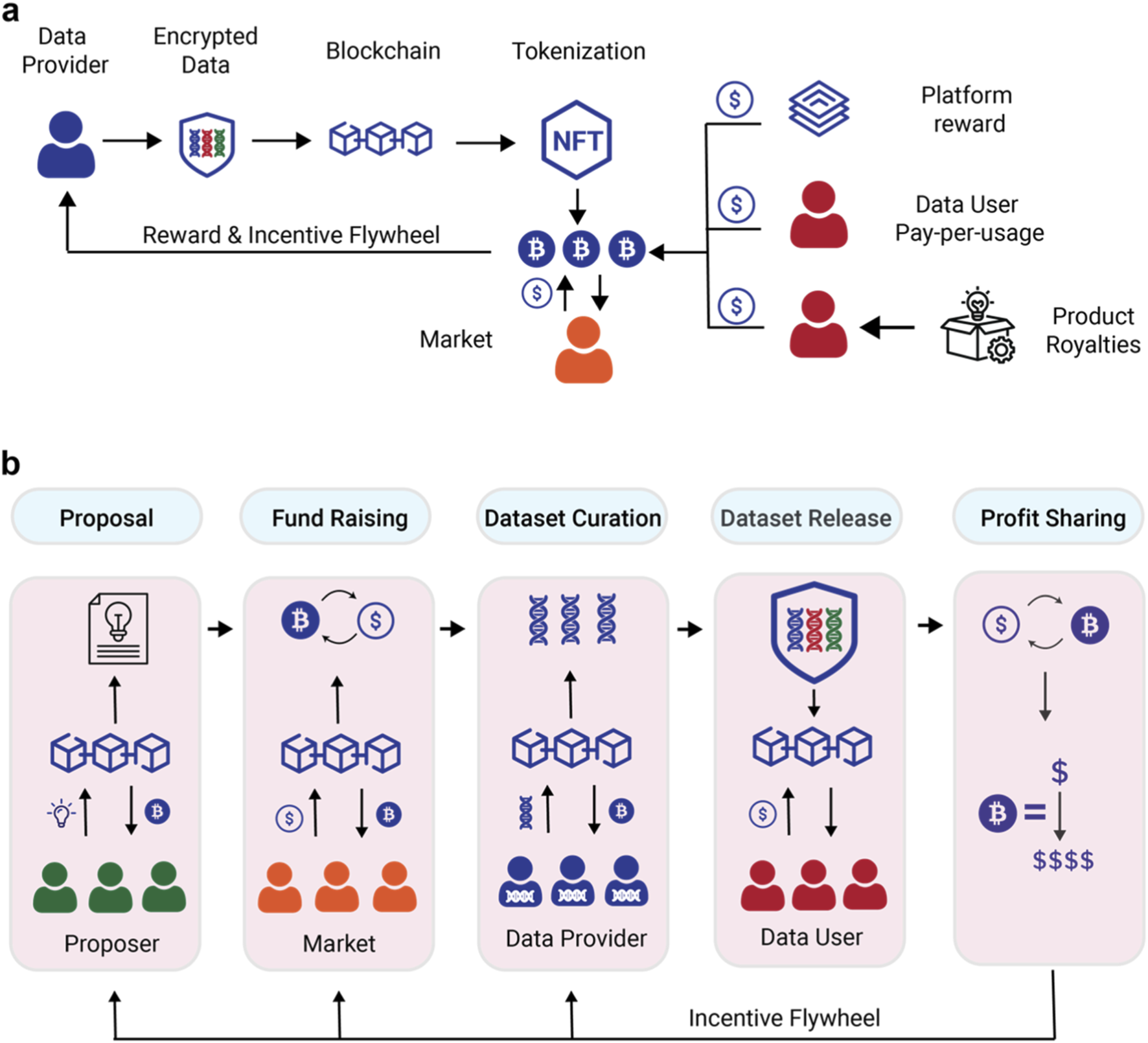
Define the total supply and distribution schedule. Ensure the contract has a built-in verification mechanism, such as requiring multiple annotators to agree on a label before releasing payment. This prevents fraud and ensures data quality from the start.
2. Configure incentive tiers
Set up different reward levels based on task complexity and accuracy. Simple classification tasks might earn fewer tokens than complex medical image annotation. Use a reputation system to increase rewards for workers with high historical accuracy scores. This encourages consistent performance and attracts experienced annotators to difficult tasks.
Implement a penalty clause for low-quality submissions. If an annotator’s work is flagged as incorrect by the majority or a verifier, they lose a portion of their expected reward. This creates a direct financial consequence for negligence, aligning worker interests with data quality.
3. Integrate the labeling interface
Connect your frontend labeling tool to the smart contract. When a worker completes a task, the interface should trigger a transaction to verify the label against the consensus mechanism. Once verified, the contract automatically transfers the agreed-upon tokens to the worker’s wallet. This eliminates the need for manual payouts and reduces administrative overhead.
Ensure the interface supports multiple wallets and blockchain networks for accessibility. Provide clear feedback to users when transactions are pending or failed. A smooth user experience is critical for retaining annotators in a competitive market.
4. Launch and monitor
Start with a small batch of tasks to test the workflow. Monitor the accuracy rates and token distribution speed. Adjust incentive tiers if you notice low participation or high error rates. Use on-chain analytics to track worker performance and identify potential bottlenecks in the verification process.

Scale up gradually as you refine the parameters. Compare the cost per labeled data point against traditional methods to validate the economic efficiency of your token-incentivized data labeling approach.
5. Verify and audit
Regularly audit the smart contract for security vulnerabilities. Use multi-sig wallets for treasury management to prevent unauthorized token minting. Review consensus logs to ensure that the verification process is fair and transparent. This builds trust with your annotator community and ensures the long-term viability of the project.
Common mistakes in token-incentivized data labeling
When you pay annotators with tokens, you are building a micro-economy. If the rules are vague or the rewards are misaligned, the quality of your training data collapses. Below are the three most frequent errors teams make when designing these systems, along with the specific fixes required to maintain accuracy.
Misaligned reward structures
The most common error is tying rewards solely to quantity rather than quality. If an annotator earns tokens for every label submitted, they will rush through tasks, often introducing noise that is more expensive to clean later.
The fix: Implement a tiered payout system. Base rewards on verified accuracy, not just volume. Use consensus mechanisms where multiple annotators label the same data point; only those who match the majority (or an expert baseline) receive the full token reward. This ensures that speed does not come at the cost of precision.
Ignoring economic volatility
Token values fluctuate. An incentive that looks generous on Monday might be worthless by Friday if the token price crashes. This volatility causes annotator churn, as workers leave for platforms with stable fiat payouts. High turnover leads to inconsistent labeling standards across your dataset.
The fix: Peg rewards to a stablecoin or offer a fiat-equivalent option. If you must use volatile tokens, build in a buffer that accounts for price swings, or allow annotators to convert their earnings immediately. Stability keeps your workforce steady and your labeling guidelines consistent.
Weak verification and fraud controls
Without rigorous checks, bad actors can game the system. They might use bots, collude with each other to fake consensus, or submit random labels to test the reward threshold. This creates a "garbage in" scenario that ruins your AI model's performance.
The fix: Integrate automated quality assurance layers. Use statistical models to detect anomalous labeling patterns, such as unusually fast completion times or low-variance responses. Combine this with periodic expert audits. Only after a data point passes these checks should the smart contract release the tokens, ensuring that every label is trustworthy.
Token-incentivized data labeling: what to check next
Token-incentivized data labeling uses blockchain smart contracts and ERC-20 tokens to reward human annotators for high-quality work. This model replaces traditional fixed-rate payments with performance-based crypto rewards, creating a decentralized system where accuracy is directly tied to compensation. Projects like Deano and Sapien use these mechanisms to scale AI training data while reducing fraud.
What is the incentive model in Blockchain?
A crypto incentive model is the system of rewards, penalties, and economic rules designed to encourage desired behavior within a blockchain network. In data labeling, this means annotators earn tokens for correct labels and lose them or face slashing for errors. This aligns the annotator’s financial interest with the project’s need for reliable training data, effectively gamifying the annotation process to improve overall dataset quality.
How do ERC-20 tokens improve labeling accuracy?
Traditional platforms often suffer from low engagement and inconsistent quality. By using ERC-20 tokens on Ethereum, platforms like DDLP (Decentralized Data Labeling Platform) create a trustless environment where smart contracts automatically verify and distribute rewards. This transparency ensures that annotators are paid fairly for verified work, while project owners receive high-integrity data without needing to vet every individual contributor manually.
Is token-based labeling secure for sensitive data?
Security is a primary concern when handling proprietary AI datasets. Blockchain-based labeling platforms typically combine on-chain token incentives with decentralized storage solutions like IPFS. This ensures that while the reward mechanism is transparent and immutable, the actual data remains encrypted and accessible only to authorized annotators, maintaining privacy while leveraging the speed and cost-efficiency of tokenized workflows.
Work through The to Token-Incentivized Data Labeling
No comments yet. Be the first to share your thoughts!