How token incentives solve the AI hallucination crisis
Token-incentivized data labeling moves beyond simple payment structures by tying compensation directly to the verifiable quality of annotated datasets. When AI models hallucinate, it is often because they were trained on noisy or biased data. By using blockchain-based incentives, platforms can reward annotators for accuracy and penalize poor work, creating a self-correcting ecosystem.
This approach relies on smart contracts to automate the distribution of rewards. For example, projects like Deano use specific tokens to incentivize community members for precise labeling, ensuring that vendors receive high-quality inputs without manual oversight. Similarly, systems employing ERC-20 tokens and decentralized storage like IPFS create trustless environments where data integrity is mathematically guaranteed rather than just contractually promised.
The result is a shift from volume-based labeling to quality-based incentives. Annotators are motivated to double-check their work because their token rewards depend on consensus or validation by other network participants. This reduces the cost of cleaning data and directly addresses the root cause of many AI reliability issues.
Why this matters for data integrity
Traditional data labeling often suffers from the "monkey see, monkey do" problem, where low-paid workers rush through tasks to maximize hourly rates. Token incentives disrupt this dynamic by making each annotation valuable in a broader economic context. If an annotator submits low-quality data, the smart contract may reject the token reward, effectively creating a financial consequence for negligence.
This system also democratizes access to AI training data. Instead of relying on a few large outsourcing firms, organizations can tap into global communities of annotators who are financially motivated to be accurate. The transparency of the blockchain ensures that every label is traceable, allowing developers to audit the provenance of their training sets.
As the AI industry grapples with the "garbage in, garbage out" dilemma, token-incentivized labeling offers a scalable solution. It aligns the economic interests of the annotator with the technical needs of the developer, creating a more robust foundation for reliable AI models.
Token-incentivized data labeling choices that change the plan
Moving to token-based rewards shifts data labeling from a simple vendor contract to a decentralized economic layer. While this approach can lower costs and increase annotator engagement through gamification, it introduces specific technical and operational risks that require careful evaluation. Before adopting an ERC-20 or similar token model, you must weigh the following concrete factors against your project’s quality requirements and budget constraints.
Security and Smart Contract Risk
Decentralized Data Labeling Platforms (DDLP) rely on Ethereum smart contracts to manage payouts and verify annotations. This trustless architecture removes the need for a central authority to hold funds, but it also means your project’s integrity depends entirely on code correctness. If the smart contract contains a vulnerability, malicious actors could exploit it to drain the incentive pool or submit fraudulent labels without penalty. Unlike traditional cloud providers where you can sue for negligence, a compromised contract often results in irreversible financial loss. You must audit the underlying code or rely on platforms with established, battle-tested contracts to mitigate this exposure.
Inflation and Token Volatility
Token incentives are only as valuable as the token’s market price. If your platform issues a fixed number of tokens per label, sudden spikes in token demand can inflate the cost per annotation, blowing through your budget. Conversely, if the token price crashes, annotators may lose motivation, leading to a drop in data quality or a mass exodus to more stable platforms. This volatility creates unpredictable operational costs. To manage this, some projects peg rewards to stablecoins or adjust the token issuance rate dynamically based on market conditions, but these mechanisms add complexity to the backend infrastructure.
Quality Control and Sybil Attacks
Traditional platforms use manual review and reputation scores to ensure accuracy. Token-based systems often use automated consensus mechanisms, where multiple annotators must agree on a label to receive payment. While this reduces the need for expensive human moderators, it opens the door to Sybil attacks, where bad actors create thousands of fake identities to farm tokens. Without robust identity verification (such as Soulbound Tokens or decentralized ID proofs), your dataset could be flooded with coordinated low-quality or adversarial labels. You need to evaluate whether the platform’s consensus mechanism is strong enough to filter out noise before it enters your training set.
Annotator Retention and Motivation
Gamification can boost short-term engagement, but it does not always correlate with long-term data quality. Annotators may prioritize speed to maximize their token yield, leading to careless labeling. Additionally, regulatory uncertainty surrounding crypto rewards in various jurisdictions can limit your pool of available workers. Some regions restrict the use of crypto for labor payments, effectively shrinking your talent base. You must consider whether your target annotators are comfortable with crypto payments and whether the platform provides stable, compliant payout methods to retain top talent over time.
Comparison: Traditional vs. Token-Incentivized Labeling
The table below summarizes the key operational differences between centralized data labeling vendors and decentralized, token-incentivized platforms.
| Factor | Centralized Vendor | Token-Incentivized Platform |
|---|---|---|
| Cost Predictability | Fixed per-label rate; budget-friendly | Variable; exposed to token volatility |
| Quality Assurance | Human review layers; established SLAs | Consensus algorithms; smart contract logic |
| Scalability | Limited by vendor capacity and hiring speed | Global; open to any token holder |
| Security Model | Corporate liability; legal recourse | Code-dependent; trustless; no central recourse |
| Regulatory Compliance | Standard labor laws; clear tax treatment | Uncertain; varies by jurisdiction |
How to choose a token-incentivized data labeling platform
Token-incentivized data labeling shifts the quality control from passive oversight to active economic alignment. Instead of paying annotators solely for volume, platforms like Deano distribute tokens (e.g., DAN) based on accuracy and consistency. This creates a win-win scenario where high-quality contributors earn more, directly reducing the hallucination risk in your AI models.
When evaluating a platform, look for these five operational mechanics that distinguish robust systems from experimental ones.
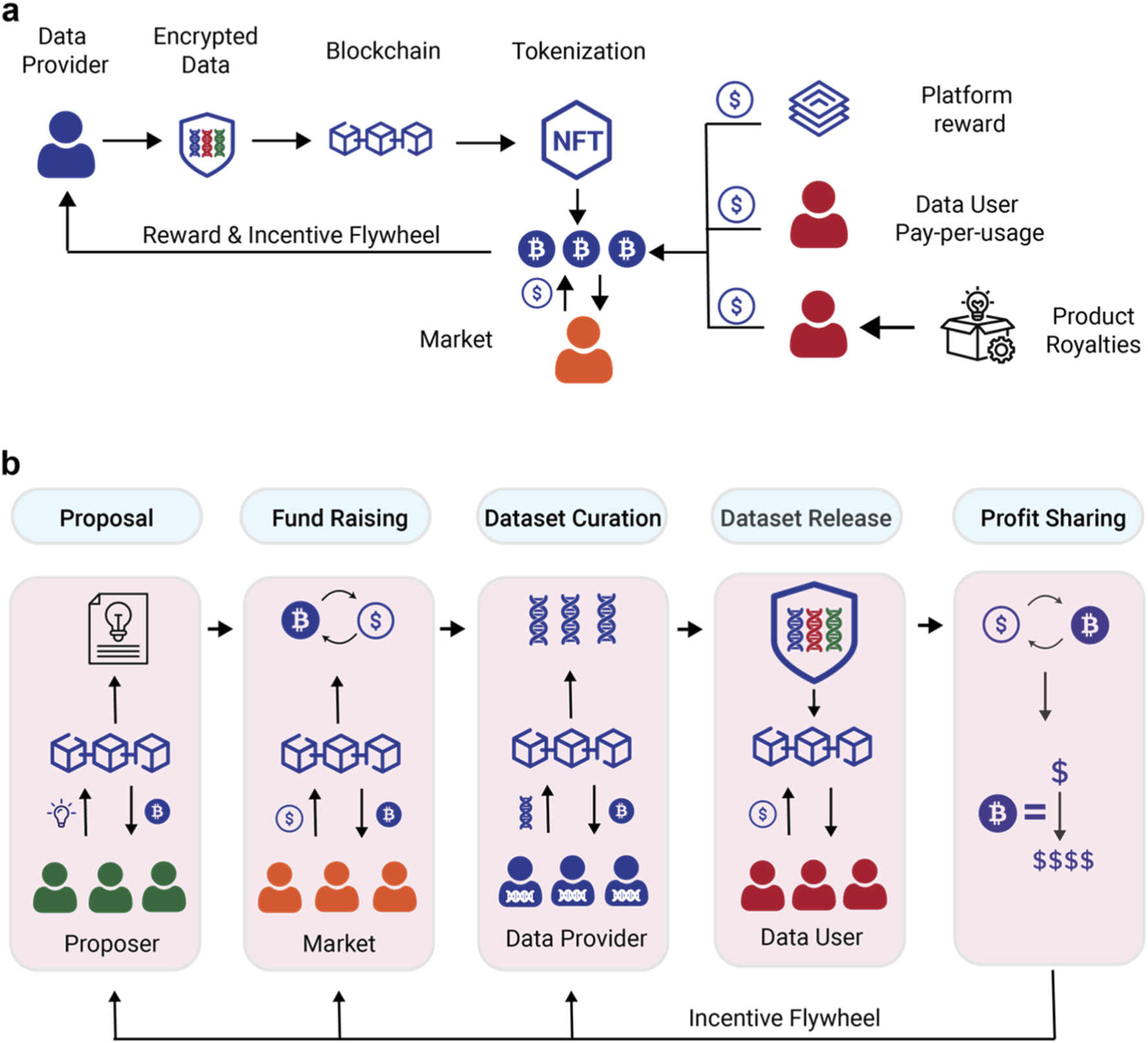
The backbone of any token-incentivized system is its smart contract. Platforms like DDLP use Ethereum contracts to automate payments and enforce rules without human intervention. This trustless environment ensures that annotators are paid instantly for verified work, reducing administrative overhead and preventing payment disputes that delay project timelines.
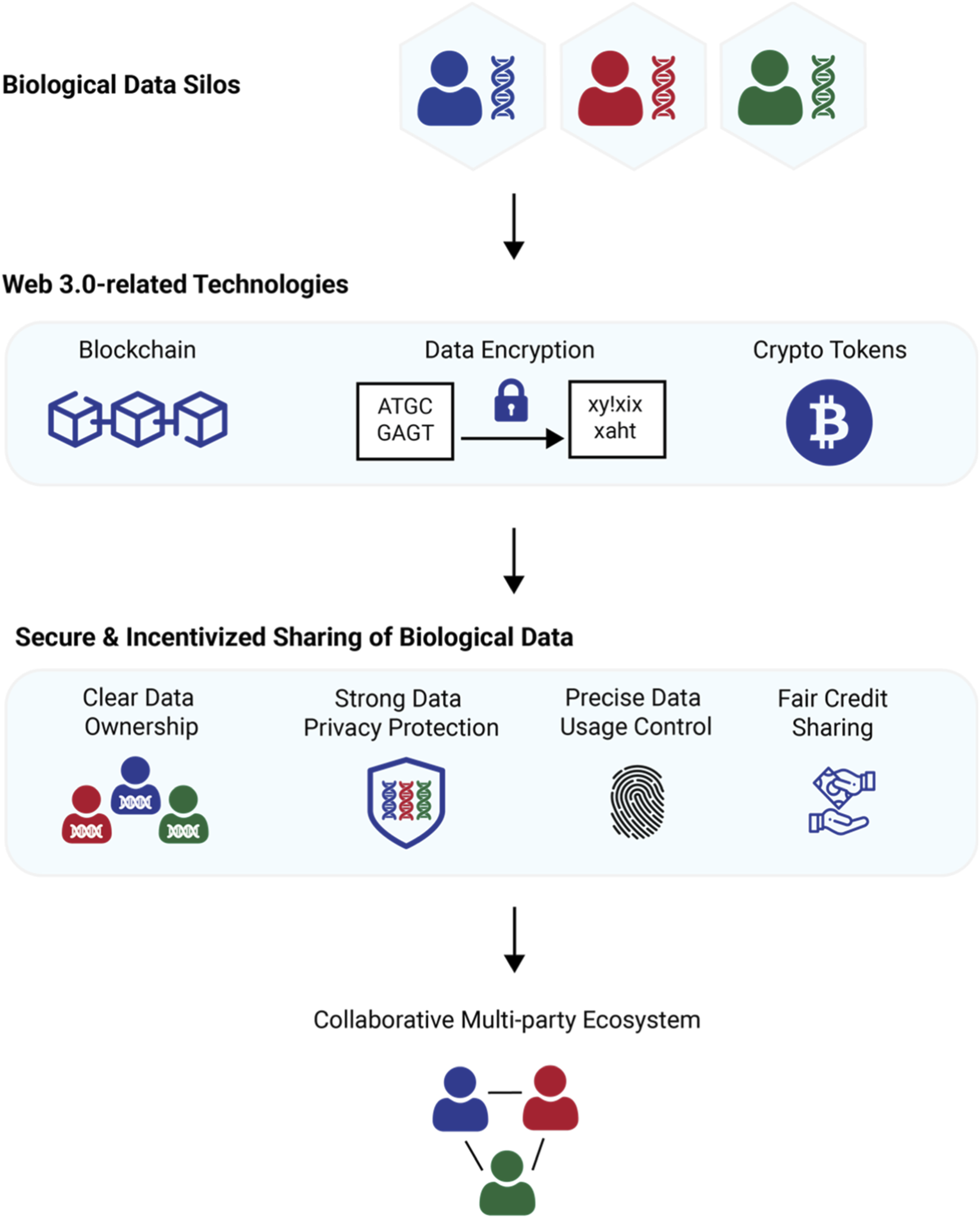
Look for platforms that pair token incentives with decentralized storage solutions like IPFS. Centralized databases are single points of failure and security risks. By storing labeled data on decentralized networks, you ensure that your training datasets remain immutable and accessible, preserving the integrity of your AI development pipeline.

Not all token rewards are equal. Effective platforms tie token distribution to specific quality metrics, such as inter-annotator agreement or expert validation results. Avoid platforms that reward only volume; this incentivizes speed over accuracy, which directly fuels AI hallucinations. The best systems penalize low-quality submissions by withholding tokens.

Some platforms, like Deano, leverage community validation where multiple annotators review the same data. Consensus among these participants triggers token rewards. This peer-review layer adds a critical quality filter, ensuring that the data feeding your models is not just labeled, but verified by a distributed network of human experts.
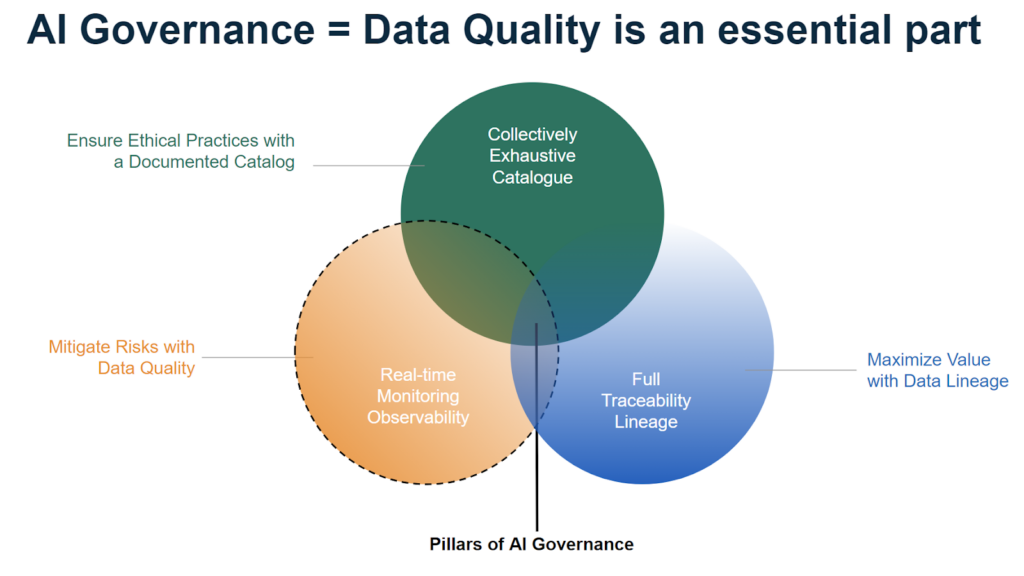
Ensure the platform’s token has clear utility beyond just payment. Can it be staked for governance? Is it liquid on major exchanges? A token with real-world value and utility attracts higher-quality annotators who are motivated by long-term ecosystem growth rather than short-term gains.
Spotting Weak Options and Misleading Claims
Token-incentivized data labeling promises to solve the AI hallucination crisis, but the market is littered with weak options that confuse technical concepts. Before committing to a platform, you need to distinguish between genuine incentive mechanisms and marketing fluff. The most common mistake is assuming that any blockchain-based data solution automatically ensures quality. It does not. Quality depends entirely on how the incentive layer is structured and enforced.
Confusing Data Tokenization with Incentive Tokens
A major source of misleading claims is the conflation of data tokenization with the incentive layer. Data tokenization, as defined by IBM, is a security measure where sensitive data is mapped to a non-sensitive token for secure storage. This is a privacy and compliance tool, not a mechanism for rewarding data labelers. Many projects use the term "tokenization" loosely to imply they are protecting data, while their actual incentive model is opaque or non-existent. You must check if the project explicitly details how ERC-20 or similar tokens are used to reward accurate labeling, as seen in projects like DDLP which use Ethereum smart contracts for this specific purpose.
The "Trustless" Trap
Another weak option is the reliance on the term "trustless" without explaining the verification process. While projects like Deano use DAN tokens to incentivize annotators, the core value is not the token itself, but the smart contract logic that verifies accuracy. If a platform claims to be trustless but offers no transparent on-chain verification of label quality, it is likely just a centralized database with a token attached. Look for concrete examples of on-chain audits or decentralized storage (like IPFS) that back up the labeling claims. Without this, the "trustless" aspect is a hollow promise that does not protect against hallucinations.
Ignoring the Incentive Layer's Real Function
The incentive layer in blockchain technology is designed to reward participants, such as miners or validators, for maintaining network integrity. In data labeling, this means rewarding labelers for consistent, high-quality work. Many weak options fail here by offering static rewards that do not scale with accuracy. A robust system adjusts rewards based on verification outcomes. If a platform offers a flat rate per label regardless of quality checks, it is incentivizing volume over accuracy, which directly contributes to AI hallucinations. Always verify that the incentive structure aligns with the goal of reducing errors, not just increasing the volume of labeled data.
No comments yet. Be the first to share your thoughts!