Define the labeling task scope
Build a Token-Incentivized Data Labeling Pipeline works best as a clear sequence: define the constraint, compare the realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative. After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.
The simplest way to use this section is to write down the real constraint first, compare each option against it, and choose the path that still works outside ideal conditions.
Design the ERC-20 reward mechanism
Token issuance must align annotator incentives with data quality. A simple per-submission model encourages low-effort labeling and spam. The mechanism should tie rewards to consensus or oracle verification, ensuring that only verified, high-quality data earns tokens.
Define Quality Metrics
Start by establishing clear quality standards. Define what constitutes a "good" label. Is it a majority vote? Does it require expert review? Use these metrics to weight token rewards. Higher quality labels receive more tokens. This creates a direct correlation between effort and compensation.
Implement Consensus Verification
Use a consensus mechanism to validate submissions. If multiple annotators label the same item, their results are compared. Disagreements are flagged for review. Only labels that pass the consensus threshold are approved. This prevents single points of failure and reduces the impact of malicious actors.
Set Token Distribution Rules
Define the total supply and distribution schedule. Consider a fixed cap to prevent inflation. Distribute tokens over time, not all at once. This ensures long-term engagement. Use smart contracts to automate payments. This reduces administrative overhead and increases trust.
Prevent Low-Effort Submissions
Implement penalties for low-quality work. Deduct tokens for incorrect labels. Ban users who repeatedly submit poor data. This discourages bad actors and maintains data integrity. The goal is to create a trustless environment where quality is rewarded and laziness is punished.
Example: FedToken Scheme
The FedToken project demonstrates a contribution-based incentive scheme. It uses blockchain technology to ensure fair allocation of tokens. Contributors are rewarded based on the value of their data. This model ensures that high-quality contributions are recognized and compensated appropriately.
Example: DDLP Platform
The Decentralized Data Labeling Platform (DDLP) uses ERC-20 tokens to provide a trustless environment. Developers and researchers can label data without relying on a central authority. The token incentives align the interests of all participants, promoting high-quality data collection.
Deploy the smart contract interface
Build a Token-Incentivized Data Labeling Pipeline works best as a clear sequence: define the constraint, compare the realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative. After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.
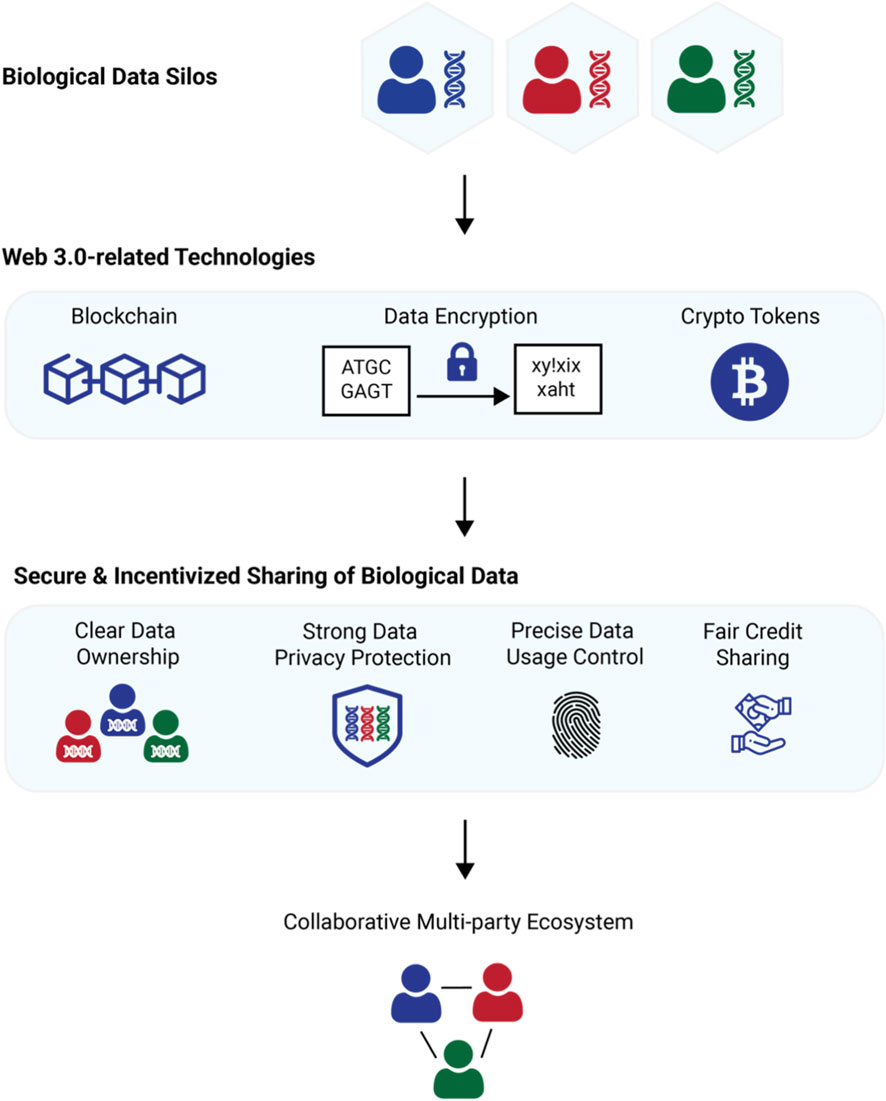
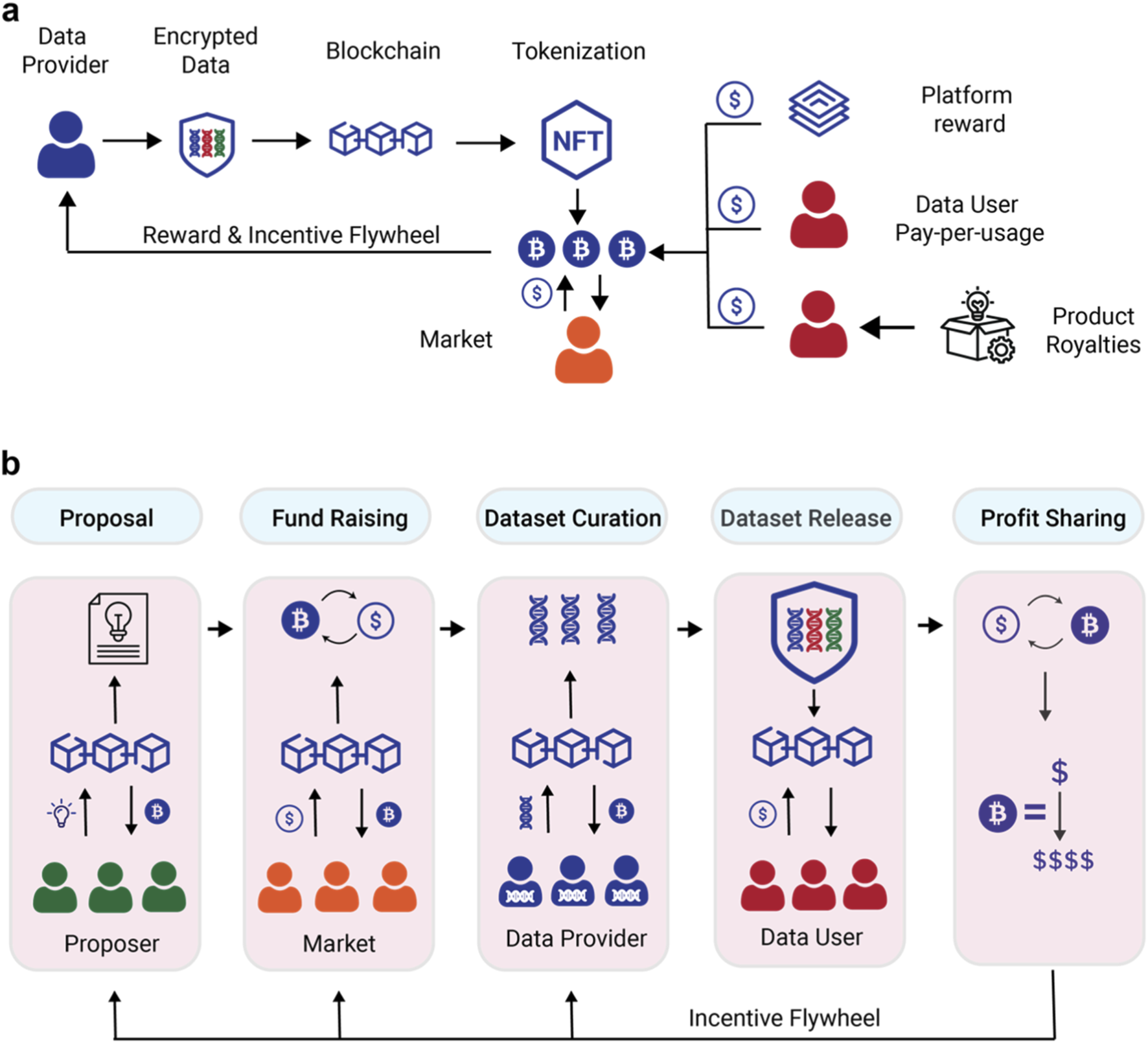
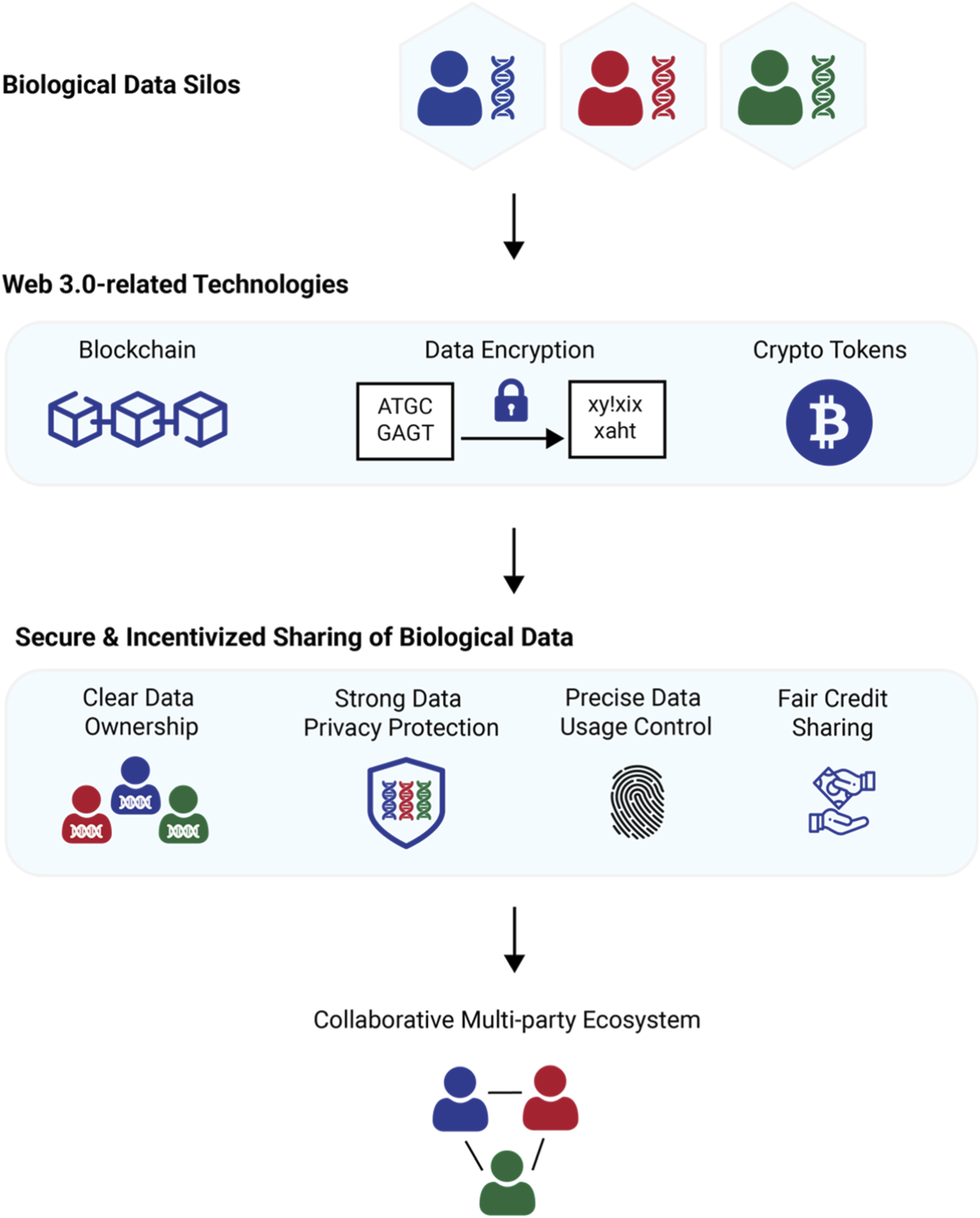
Implement quality assurance protocols
Token-incentivized pipelines rely on economic friction to maintain data integrity. Without strict validation, the system becomes vulnerable to sybil attacks and low-effort labeling. You must structure your quality assurance (QA) process to penalize noise and reward precision.
Multi-annotator consensus
Require multiple independent annotators to label the same data point before it enters the training set. This approach identifies outliers and reduces individual bias. Configure your smart contracts to calculate a confidence score based on agreement rates. If consensus is not reached, the data is either discarded or routed to a senior reviewer for arbitration.
AI pre-filtering
Deploy a lightweight, open-source model to pre-screen incoming data. This AI acts as a gatekeeper, flagging obvious errors, duplicates, or adversarial inputs before human labelers engage. By filtering out low-quality submissions early, you preserve token rewards for annotators who handle genuinely difficult edge cases. This step significantly reduces the cost per valid label.
Reward slashing conditions
Define clear penalty structures for annotators who consistently fail quality checks. Use a slashing mechanism that deducts tokens from their stake when their labels deviate significantly from the ground truth or consensus. This aligns economic incentives with accuracy, ensuring that high-quality contributions are sustained over time.
No comments yet. Be the first to share your thoughts!