Get token-incentivized data labeling right
Before launching a labeling campaign, you need to align three moving parts: the smart contract logic, the annotator experience, and the quality verification layer. If any of these are misaligned, you will either attract bad actors or pay for low-quality outputs. This section covers the prerequisites for setting up a robust system.
1. Define the token economics
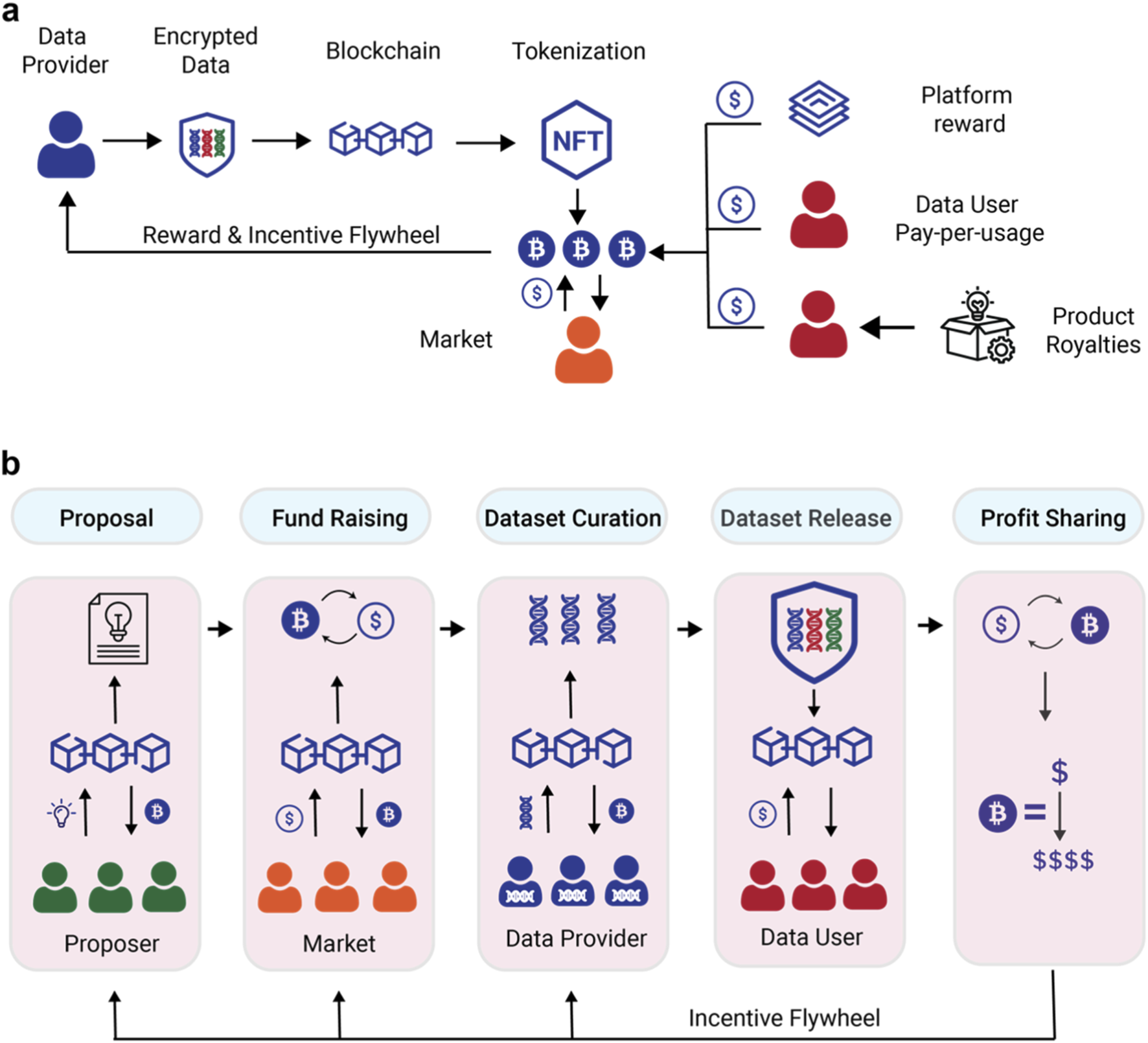
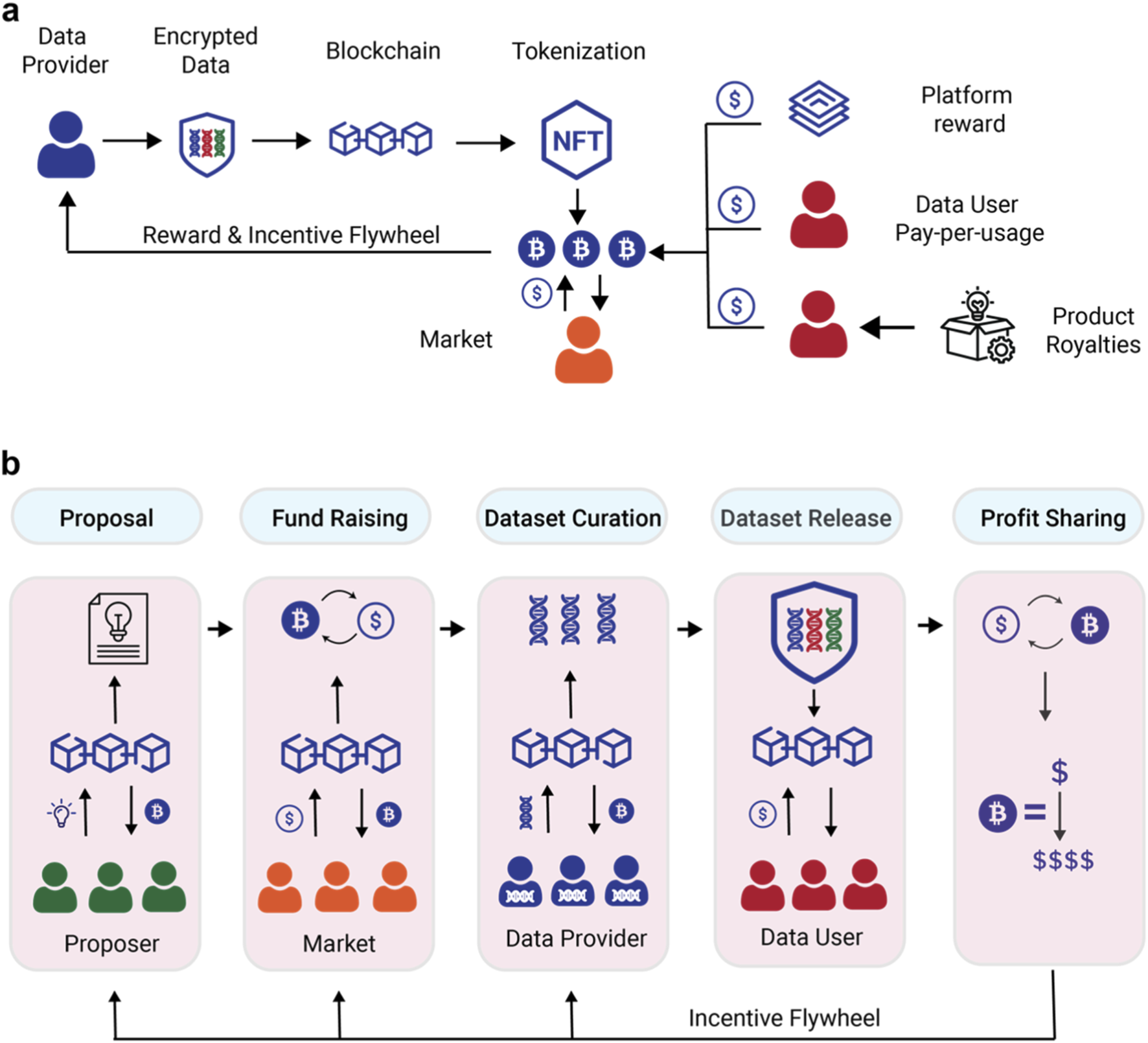
Your incentive model must balance cost with accuracy. A flat fee per label attracts volume but not quality. Instead, structure rewards around consensus or verified accuracy. For example, systems like Deano use DAN tokens to reward annotators who consistently produce high-fidelity labels, creating a win-win for vendors and data providers. Ensure the token value is stable enough to attract skilled workers but volatile enough to prevent gaming if you are using a pure crypto model.
2. Choose the right infrastructure
You need a trustless environment to handle payments and label storage securely. The Data Labeling Protocol (DDLP) demonstrates this by combining Ethereum smart contracts with decentralized storage via IPFS. This setup ensures that once a label is submitted and verified, it cannot be altered, and payments are executed automatically without a middleman. This transparency is critical for high-stakes training data where audit trails matter.
3. Set up quality gates
Token incentives alone do not guarantee quality. You must implement a verification layer. This could be a majority-vote system where multiple annotators label the same item, or a expert-review layer for edge cases. Without this, malicious actors can farm tokens by submitting random or low-effort labels. Define your acceptance criteria clearly in the smart contract logic so that rewards are only released upon successful verification.
4. Test the annotator flow
Before scaling, run a small pilot. Send a batch of 50-100 labeled items to a small group of annotators. Track their completion time, error rates, and token earnings. This helps you calibrate your reward rates and identify friction in the user interface. If the process is too complex, annotators will drop out; if it is too simple, you will get low-quality data.
Work through the steps
Scaling high-quality AI training data requires a structured approach to token-incentivized labeling. By combining smart contract logic with decentralized storage, you can automate payments and ensure data integrity without relying on a central authority. This process turns data annotation into a trustless, transparent workflow.
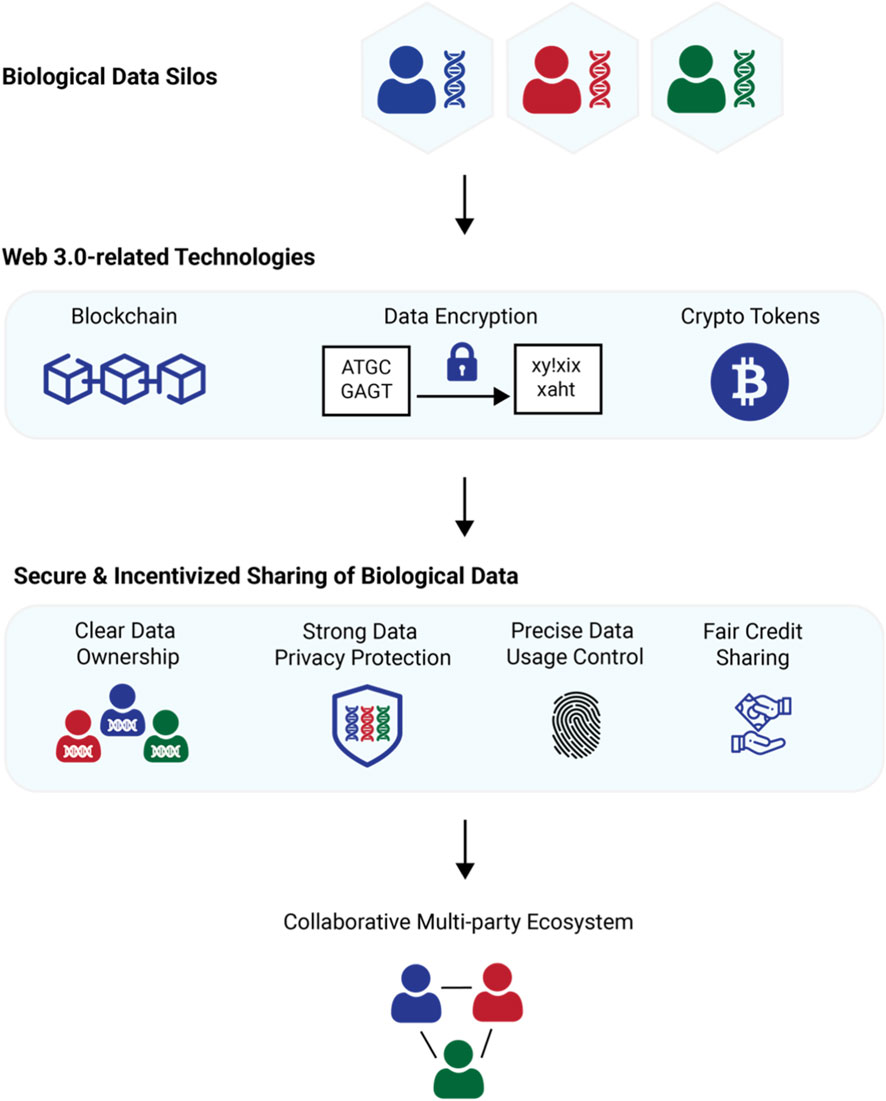
Begin by deploying an ERC-20 token contract on your chosen blockchain, such as Ethereum. This contract defines the reward currency for annotators. You must also configure the contract to handle escrow, ensuring funds are locked until the data is verified. This step creates the economic backbone of your labeling pipeline.
Connect your smart contract to a decentralized storage network like IPFS. Raw data and its resulting labels should be stored here rather than on-chain to keep gas costs low. The smart contract will store only the IPFS hashes, creating an immutable link between the payment logic and the actual data files.
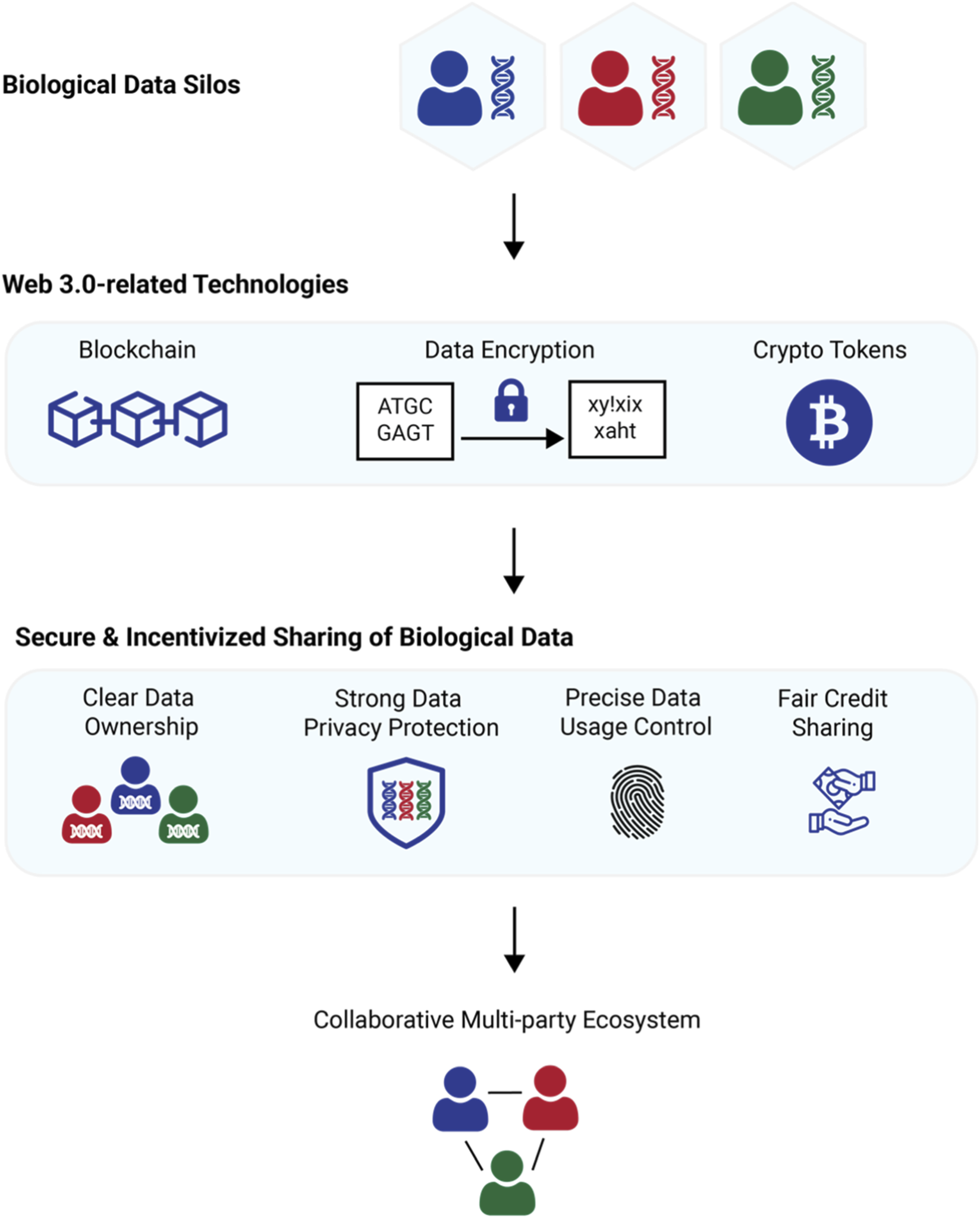
Break your dataset into manageable chunks and assign them to annotators. Clearly specify the labeling schema—whether it’s bounding boxes for images, sentiment tags for text, or classification categories. Use a reputation system to route difficult tasks to high-scoring annotators, ensuring that complex data gets the most skilled attention.
To prevent low-quality submissions, implement a consensus mechanism. Require multiple annotators to label the same data point independently. The smart contract compares these submissions; if they match within a set threshold, the data is accepted. If they diverge, the task is flagged for review by a senior annotator or an oracle network.
Once the verification logic confirms the data is accurate, the smart contract automatically releases the ERC-20 tokens to the annotators’ wallets. This atomic payment removes administrative overhead and ensures annotators are compensated immediately, which is critical for maintaining a steady workforce in a decentralized environment.
Fix Common Mistakes in Token-Incentivized Labeling
Even with robust blockchain infrastructure, poor execution in the labeling workflow can degrade model performance. The following errors frequently undermine the quality of token-incentivized datasets.
Misaligned Token Economics
Designing a flat token reward for all tasks ignores the varying difficulty of annotations. If complex medical imaging labels pay the same as simple text categorization, annotators will rush through difficult tasks to maximize earnings. This leads to inconsistent quality that is hard to filter out later. Adjust rewards based on task complexity and verification difficulty to ensure annotators invest the necessary effort.
Inadequate Verification Mechanisms
Relying solely on smart contract payouts without rigorous quality control allows low-effort or malicious annotations to pass. If the verification layer is weak, bad data enters the training set, directly harming model accuracy. Implement multi-stage verification, such as requiring consensus from multiple annotators or integrating automated sanity checks before releasing tokens.
Ignoring Annotator Context
Treating annotators as anonymous workers rather than skilled contributors leads to high churn and disengagement. Without clear guidelines or feedback loops, annotators make the same errors repeatedly. Provide detailed labeling instructions and regular feedback on performance to help annotators improve. This builds a more reliable and committed labeling community.
Token-incentivized data labeling: what to check next
Before committing to a decentralized labeling workflow, it helps to understand the mechanics behind the tokens and the quality controls that keep them honest. The following answers address the most common practical objections raised by data engineers and project managers.
No comments yet. Be the first to share your thoughts!