Why token incentives matter for AI data
The traditional data labeling industry operates on a static, centralized model that struggles to scale with the exponential growth of AI training requirements. Centralized platforms often face bottlenecks in quality control and high operational costs, creating a structural inefficiency that limits the availability of high-fidelity training data. This bottleneck is particularly acute in sectors requiring specialized domain knowledge, where the cost of human annotation becomes prohibitive.
Token-incentivized data labeling introduces a dynamic economic layer to this process. By leveraging blockchain architecture, platforms can distribute rewards instantly and adjust compensation based on the verified quality of the data contributed. This shift transforms data annotation from a passive labor task into an active, market-driven participation model. As noted in research on Decentralized Data Labeling Platforms (DDLP), ERC-20 tokens enable smart contracts to automate these incentives, ensuring that contributors are rewarded proportionally to the value and accuracy of their inputs.
This mechanism addresses the core problem of data scarcity and quality degradation. In a centralized system, quality checks are often retrospective and expensive. In a tokenized ecosystem, consensus mechanisms and reputation scores embedded in the blockchain allow for real-time validation. This reduces the need for expensive third-party auditors and lowers the overall cost of acquiring training datasets. The result is a more resilient and scalable infrastructure for AI development, where data quality is economically enforced rather than contractually mandated.
The transition to token-based incentives is not merely a technological upgrade but a fundamental restructuring of the data economy. It allows for global participation, reducing reliance on a limited pool of centralized annotators. As AI models become more complex, the ability to rapidly aggregate and verify diverse, high-quality data points becomes a competitive advantage. Token incentives provide the liquidity and motivation necessary to sustain this aggregation at scale.
How decentralized annotation platforms work
Decentralized annotation platforms function as automated marketplaces where data labeling is treated as a liquid asset. Instead of relying on centralized vendors, these systems utilize smart contracts to manage the entire lifecycle of a labeling task. The process begins when a data provider deposits raw datasets and defines quality parameters into a smart contract. This contract acts as the escrow agent, holding the tokenized payment until the work is verified. By removing the middleman, platforms reduce overhead costs and create a global labor pool that can scale up or down based on immediate market demand.
The incentive structure relies on ERC-20 token distribution to align the interests of annotators with data quality. When an annotator completes a task, the smart contract automatically releases tokens to their wallet. However, payment is not immediate; it is contingent on verification. This mechanism mirrors traditional freelance marketplaces but replaces fiat currency with programmable digital assets. The use of tokens allows for micro-transactions that are economically viable, enabling granular rewards for small, high-precision labeling tasks that would be inefficient to process through traditional banking channels.
Automated quality verification ensures that the data feeding into AI models meets rigorous standards. Platforms typically employ a consensus mechanism where multiple annotators label the same data point. The smart contract compares these submissions against a predefined threshold of agreement. If the annotators’ labels match the consensus, the tokens are released. If they deviate, the task is flagged for review or the annotator faces a penalty, such as a temporary suspension or a reduction in future task eligibility. This automated audit trail creates a transparent record of data provenance, which is critical for debugging machine learning models later in the training pipeline.
The economic efficiency of this model is reflected in the broader crypto-AI market. As demand for high-quality training data grows, the value of tokens associated with these platforms often correlates with the performance of underlying AI infrastructure. Investors and developers monitor these metrics to gauge the health of the decentralized data economy.
This integration of blockchain logic with data science creates a self-regulating ecosystem. The smart contract enforces the rules, the tokens provide the motivation, and the consensus mechanism guarantees the output. For AI developers, this means access to a more flexible and cost-effective supply chain for training data, while annotators benefit from transparent, immediate compensation for their labor.
Token economics as a quality enforcement mechanism
Traditional crowdsourcing platforms operate on a flat-rate model, paying labelers a fixed fee regardless of the accuracy of their output. This structure creates a misalignment of incentives: the worker’s goal is to maximize volume, while the buyer’s goal is precision. Token-incentivized data labeling inverts this dynamic by introducing dynamic rewards and staking mechanisms that tie compensation directly to data quality.
In this model, labelers often stake tokens before beginning a task. If their annotations pass automated validation or consensus checks against other labelers, they earn a reward plus a share of the staked pool. If their work is flagged as inaccurate, they lose a portion of their stake. This economic friction forces participants to treat data annotation with the same rigor as financial trading.
The result is a self-correcting ecosystem where high-quality contributors are rewarded exponentially more than low-effort workers. Platforms like Sapien have leveraged this approach, raising venture capital to build systems where gamified token rewards drive higher accuracy than traditional flat-rate models. By making accuracy the most profitable path, token economics effectively automates quality control.
| Model | Cost Structure | Speed | Accuracy |
|---|---|---|---|
| Traditional Crowdsourcing | Flat fee per item | High | Low to Medium |
| Token-Incentivized | Dynamic reward + stake | Medium | High |
Real-world examples in the decentralized ecosystem
Theoretical models for token-incentivized data labeling are now being stress-tested by active protocols. Two projects, Deano and Sapien, illustrate how blockchain-based rewards can structure the labor market for AI training data. These platforms move beyond simple gig-work structures by tying compensation directly to the verifiable quality of annotations.
Deano, showcased at ETHGlobal, operates on a community-driven model where annotators earn DAN tokens for accurate data labeling. This approach creates a direct feedback loop: higher accuracy yields higher rewards, aligning the incentives of the labeler with the needs of the AI vendor. The protocol leverages blockchain transparency to ensure that the labor provided is both verifiable and fairly compensated, reducing the friction typically associated with centralized data collection.
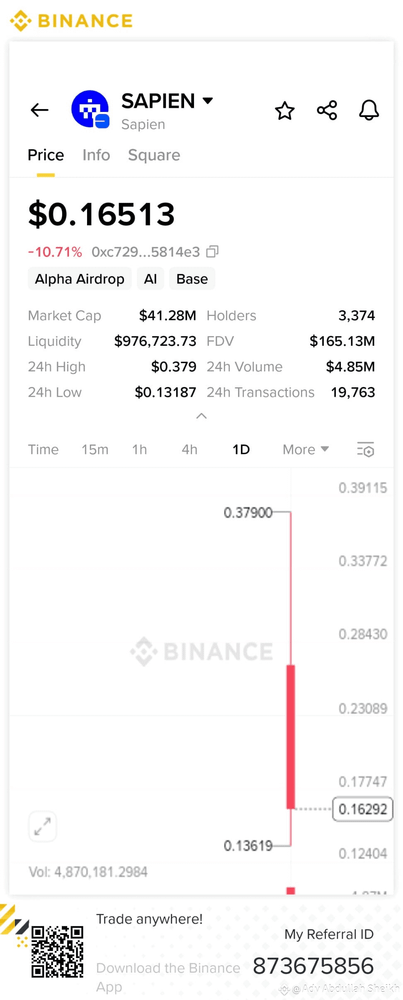
Sapien has taken a similar path, recently raising $5 million to scale its gamified data labeling infrastructure. By integrating blockchain-based rewards, Sapien incentivizes human labelers to deliver precise notations rather than rushing through tasks. This economic layer is critical for high-stakes AI training, where the cost of poor data quality far outweighs the savings from cheap, low-effort labor.
Market trends and adoption in 2026
The market for token-incentivized data labeling is shifting from experimental pilots to structured capital deployment. In 2026, the primary driver is not just the availability of data, but the economic efficiency of acquiring high-quality annotations. Traditional centralized labeling firms face margin compression as AI models require exponentially more training data, creating a vacuum that decentralized networks are positioned to fill.
Funding trends reflect this pivot. Early-stage ventures like Sapien, which raised $5 million to gamify data labeling through blockchain-based rewards, signal investor confidence in tokenized incentive structures. These models lower the barrier to entry for labelers while providing verifiable proof of work for dataset quality. The capital is flowing toward platforms that can prove their data integrity through on-chain metrics rather than just volume.
The demand for high-quality AI datasets is outpacing supply, particularly in specialized domains like medical imaging and autonomous driving. Token incentives align the interests of data contributors with model developers, reducing the fraud and noise that plague traditional crowdsourcing. As we analyze the liquidity and market interest in this sector, the performance of major AI-focused crypto assets serves as a proxy for broader market sentiment.
Frequently asked questions about token labeling
How does data labeling work?
Data labeling is the process of annotating raw data with meaningful tags, providing the context and categorization that machine learning models need to interpret information. These labels serve as essential guides, enabling algorithms to distinguish between different data points and learn patterns effectively. Without accurate labeling, ML models lack the structured input required for reliable training.
What is the incentive model in blockchain?
A crypto incentive model uses rewards, penalties, and economic rules to encourage specific behaviors within a network, such as securing the chain or providing liquidity. In the context of data labeling, platforms like Deano use this framework to distribute profits instantly. Annotators are incentivized with tokens like DAN for accurate labeling, creating a system where data quality directly correlates with economic reward.
What is DeFi tokenization?
DeFi asset tokenization involves converting real-world assets or rights into digital tokens that can be traded on blockchain platforms. This process lowers barriers to entry by allowing fractional ownership and increasing accessibility. For data labeling, tokenization transforms the labor of annotation into a tradable asset, allowing contributors to earn and hold value derived from the data they produce.
No comments yet. Be the first to share your thoughts!