The Market Shift Toward Decentralized Labeling
The artificial intelligence data market is undergoing a structural rupture. For years, centralized legacy platforms have dominated the data labeling landscape, acting as gatekeepers that control quality assurance and pricing. This model, while stable, is hitting hard limits in scalability and cost efficiency as model parameters explode into the trillions. The traditional approach treats data annotation as a manual, low-skill labor arbitrage, creating bottlenecks that stifle innovation.
Decentralized models are emerging as the necessary counterweight to this centralized inertia. By leveraging blockchain infrastructure, these platforms distribute the labeling workload across a global network of contributors rather than relying on a few large vendors. This shift is not merely technical; it is economic. Token incentives align the interests of data providers, annotators, and AI developers, creating a liquid market for high-quality training data.
The transition is driven by the urgent need for verified, privacy-preserving data sources. Centralized databases are increasingly scrutinized for security risks and regulatory compliance. Decentralized labeling offers a transparent, immutable ledger of data provenance, ensuring that the models powering the next generation of AI are trained on data that is both authentic and ethically sourced. This is the foundation of the 2026 AI training shift.
Mechanics of ERC-20 token incentives
The transition to decentralized data labeling relies on a precise economic engine where ERC-20 tokens serve as the primary mechanism for aligning annotator behavior with model accuracy. Unlike traditional centralized platforms that pay fixed wages regardless of output quality, token-incentivized networks embed quality control directly into the smart contract logic. This structure transforms data annotation from a passive labor task into an active, financially motivated audit process, ensuring that the resulting training datasets are both robust and reliable.
At the core of this system is the Decentralized Data Labeling Platform (DDLP), an architecture detailed in recent IEEE research. The platform utilizes Ethereum smart contracts to automate the distribution of rewards and the enforcement of penalties. When an annotator submits a label, the contract does not immediately release the full payment. Instead, it holds the tokens in escrow while a consensus mechanism—often involving multiple independent annotators reviewing the same data point—validates the accuracy. Only when the majority agrees does the smart contract release the ERC-20 tokens to the correct contributor. This "stake-and-validate" model significantly reduces the risk of malicious data poisoning or low-effort submissions.

Annotators receive data batches via the platform interface. They apply labels based on specific guidelines, which are encoded into the smart contract's validation rules.

The submission enters a verification queue. Other community members, often incentivized by smaller token rewards for auditing, review the label. The contract compares submissions to determine if a consensus threshold is met.

Once consensus is reached, the smart contract automatically transfers the agreed-upon ERC-20 tokens to the annotator's wallet. If the label is deemed incorrect or malicious, the contract may slash a portion of the annotator's stake, creating a financial disincentive for poor quality.
The economic viability of this model depends on the token's utility and liquidity. Projects like Deano, showcased at ETHGlobal, demonstrate how specific tokens (such as DAN) can be used to create a closed-loop economy where annotation work buys access to premium AI tools or data sets. This creates a self-sustaining ecosystem where the value of the data directly correlates with the value of the token, encouraging long-term participation. The market context for these tokens is volatile, making real-time price tracking essential for understanding the true cost of data acquisition.
The integration of these financial mechanics ensures that data labeling is not just a technical necessity but a financially sustainable industry. By leveraging the transparency and immutability of blockchain, organizations can source high-quality training data without the overhead of traditional management structures. The result is a more efficient, auditable, and scalable approach to AI development, where every token transferred represents a verified unit of truth.
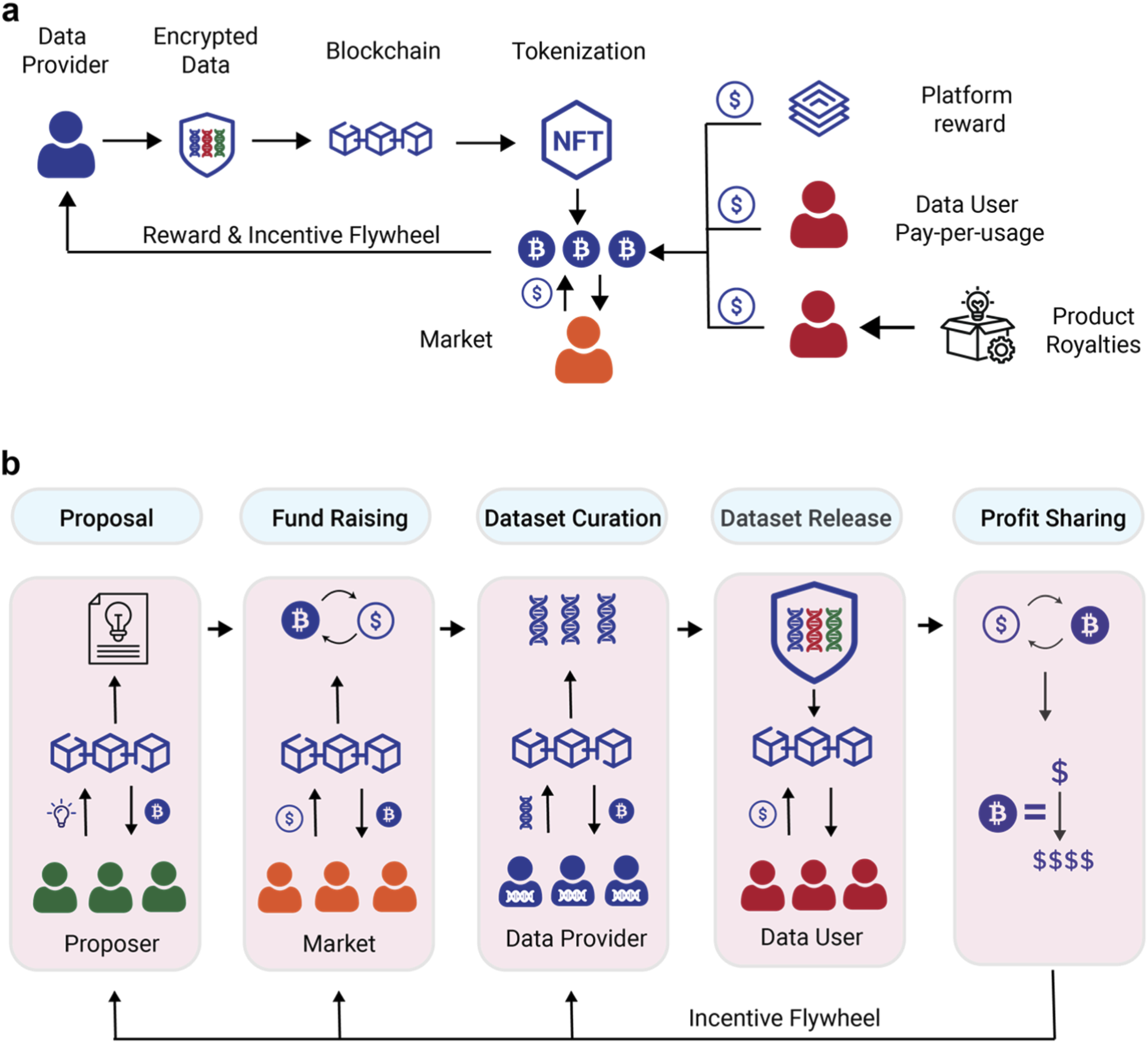
Privacy preservation through decentralization
Centralized data hubs present a single, high-value target for cybercriminals. When a single entity controls the aggregation of sensitive training data, a breach exposes the entire dataset. Decentralized data markets mitigate this risk by distributing data sovereignty across a network of nodes. This architecture ensures that no single point of failure exists, fundamentally altering the risk profile for enterprise AI adoption.
In a decentralized model, data contributors retain ownership and control over their information. Sensitive data can be encrypted and accessed only through permissioned smart contracts, ensuring that raw data remains with the owner while model updates are shared. This approach aligns with emerging data sovereignty regulations, such as the EU’s AI Act, which demand strict transparency and control over personal information used in training.
The incentive structure further reinforces privacy. Contributors are rewarded for providing high-quality, verified data without surrendering their underlying assets. This economic alignment encourages participation while maintaining the integrity of the dataset. As AI models become more complex, the ability to train on diverse, privacy-preserving data sources will be a decisive competitive advantage.
For investors and developers, the shift toward decentralized data markets represents a move from opaque, centralized control to transparent, user-centric governance. This transition is not just a technical upgrade but a fundamental restructuring of how AI training data is sourced, secured, and monetized.
Quality control and fraud mitigation
Decentralized data labeling introduces a fundamental tension: how to verify accuracy without a central authority to enforce standards. In traditional centralized models, quality assurance is an internal operational cost. In token-incentivized networks, it becomes a cryptographic and economic challenge. The primary risk is not just poor data, but deliberate fraud—labelers gaming the system to harvest rewards with low-effort or malicious annotations.
Smart contracts serve as the automated auditor. Instead of relying on human supervisors, these protocols encode quality metrics directly into the code. When a labeler submits work, the contract evaluates it against consensus rules or reference datasets. If the output meets the predefined accuracy threshold, the reward is released. If it falls short, the transaction is rejected. This removes subjective bias and ensures that every payout is tied to verifiable performance.
To further deter bad actors, systems employ token slashing. This mechanism requires labelers to stake tokens before beginning work. If fraud is detected—whether through consensus disagreement or post-hoc auditing—the staked assets are confiscated and burned. The threat of financial loss creates a high-stakes environment where accuracy is economically rational. As noted by Sahara AI, aligning incentives to reward quality over quantity is essential; without slashing, the system is vulnerable to "label spam" that dilutes model training data.
The result is a self-correcting ecosystem. Bad data is filtered out before it enters the training pipeline, and bad actors are financially disincentivized. This shifts quality control from a reactive human review process to a proactive, algorithmic guarantee.
| Feature | Centralized | Token-Incentivized |
|---|---|---|
| Cost Structure | High overhead (salaries, management) | Variable (pay-per-accurate-label) |
| Speed | Limited by team size | Scalable to thousands of workers |
| Fraud Mitigation | Human review (slow, subjective) | Smart contracts + slashing (instant, objective) |
| Privacy | Data siloed with one entity | Distributed, often encrypted |
Adoption challenges for 2026
Token-incentivized data labeling faces a triad of structural barriers that could slow market penetration in 2026. While the promise of decentralized annotation is clear, the practical reality involves navigating regulatory ambiguity, user experience friction, and the inherent volatility of crypto assets.
Regulatory uncertainty remains the most significant hurdle. As platforms tokenize social media engagements and data contributions, they operate in a legal gray area regarding data privacy and intellectual property rights. Unlike traditional centralized entities, decentralized networks struggle to comply with evolving frameworks like the GDPR or emerging AI-specific regulations, creating compliance risks for early adopters.
User experience friction further complicates adoption. The process of bridging fiat currency to crypto wallets, managing private keys, and understanding tokenomics adds layers of complexity that deter non-technical annotators. If the onboarding process is not seamless, the quality and quantity of labeled data will suffer, undermining the model training pipeline.
Finally, token volatility poses a direct threat to economic stability. Annotators rely on predictable compensation for their labor. If the value of the incentive token fluctuates wildly, the financial incentive erodes, leading to churn and inconsistent data quality. Market participants must weigh these risks against the potential efficiency gains of decentralized labor markets.
No comments yet. Be the first to share your thoughts!