What token-incentivized data labeling is
Token-incentivized data labeling replaces the traditional low-wage gig economy model with a blockchain-based reward system. Instead of relying on centralized platforms that often pay annotators minimal wages for repetitive tasks, this approach uses cryptocurrency tokens to compensate human workers. The goal is to align the interests of the data providers with the AI developers who need high-quality training data.
In this system, smart contracts automate the distribution of rewards. When an annotator submits a label, the contract verifies its quality—often through consensus mechanisms where multiple workers label the same data point. If the label meets the predefined quality standards, the smart contract releases tokens to the worker. This automation reduces administrative overhead and ensures transparency in how payments are calculated and distributed.
The primary advantage of token-incentivized data labeling is the potential for higher and more immediate compensation for annotators. By removing the middleman, more value flows directly to the workers. For AI vendors, this model can attract a more dedicated and skilled workforce, as workers are financially motivated to maintain high accuracy rather than rushing through tasks. Research into decentralized data labeling platforms (DDLP) suggests that this structure can lead to more robust and reliable datasets for machine learning models [[src-serp-1]].
KeyTakeaways
- Token-incentivized data labeling uses blockchain tokens to reward annotators, replacing low-wage gig platforms.
- Smart contracts automate payments based on quality verification, ensuring transparency and efficiency.
- This model aligns annotator and AI vendor interests by offering higher compensation for accurate work.
Why traditional labeling fails in 2026
Modern AI models have outpaced the human capacity to label data at the necessary scale. As foundation models grow more complex, the demand for high-quality training data has become a critical bottleneck. Traditional centralized outsourcing models, which rely on low-cost, high-volume labor, are no longer sufficient to meet these escalating requirements. The result is a dataset that is both too small and too noisy to support next-generation AI capabilities.
The core issue with centralized labeling is misaligned incentives. When workers are paid per item regardless of quality, the economic reward encourages speed over accuracy. This leads to "data pollution," where incorrect or low-effort labels degrade model performance. As noted by industry experts, traditional data labeling is collapsing because it cannot effectively distinguish between high-quality contributions and quantity-driven spam. Without a mechanism to verify and reward genuine expertise, the integrity of the training data suffers.
Token-incentivized data labeling addresses this failure by introducing economic alignment. Instead of a flat fee, contributors earn tokens based on the verified quality of their work. This shifts the focus from mere volume to precision, ensuring that the data used to train AI models is both abundant and reliable. By leveraging blockchain-based verification, this approach creates a sustainable ecosystem where quality is directly rewarded, solving the fundamental scalability and integrity issues of traditional methods.
How ERC-20 rewards drive quality
Token-incentivized data labeling relies on smart contracts to automate the distribution of rewards based on the accuracy of the work submitted. Instead of relying on manual verification or fixed hourly wages, these systems use Ethereum-based protocols to evaluate each label against a consensus standard. If a worker’s annotation aligns with the majority of verified labels, the smart contract automatically releases the agreed-upon ERC-20 tokens to their wallet. This mechanism removes administrative friction and ensures that compensation is directly tied to output quality rather than time spent.
The economic incentive structure is designed to discourage low-effort labeling. Because tokens hold real-world value, contributors are financially motivated to perform due diligence. In systems like the Decentralized Data Labeling Platform (DDLP), workers may also face penalties or slashing conditions for submitting incorrect data, creating a self-regulating ecosystem where quality is economically enforced rather than just monitored. This alignment of interests ensures that the data used to train AI models is both abundant and reliable.
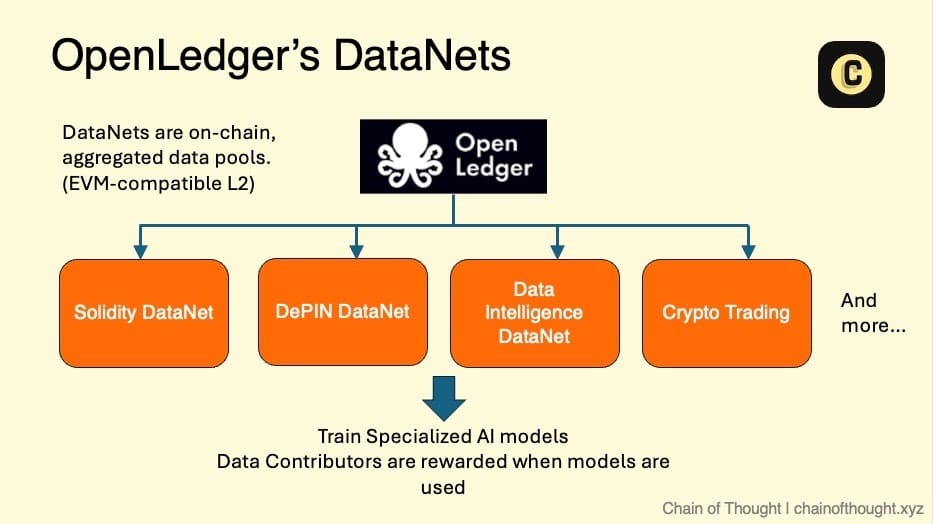
By tying financial rewards to precision, token-incentivized data labeling solves the scalability bottleneck that has long plagued AI development. Workers are no longer anonymous, low-paid contractors but incentivized participants in a decentralized network, where their contribution to model accuracy is directly reflected in their earnings.
Real-world platforms using this model
Use this section to make the Token-Incentivized Data Labeling decision easier to compare in real life, not just on paper. Start with the reader's actual constraint, then separate must-have requirements from details that are merely nice to have. A practical choice should survive normal use, maintenance, timing, and budget. If a recommendation only works in an ideal situation, call that out plainly and give the reader a fallback path.
The simplest way to use this section is to write down the must-have criteria first, then compare each option against those criteria before weighing nice-to-have features.
The Risks of Decentralized Annotation
Token-incentivized data labeling introduces specific vulnerabilities that centralized systems do not face. The most immediate threat is the sybil attack, where bad actors create multiple fake identities to farm rewards. Without robust identity verification, the cost of gaming the system can be lower than the value of honest contribution, flooding the dataset with low-quality or adversarial labels.
Token volatility further complicates the economics. If the reward token crashes in value, annotators may abandon the platform, leading to data scarcity. Conversely, if the token surges, it may attract speculative participants rather than skilled labelers, degrading the signal-to-noise ratio. This instability makes it difficult to maintain consistent quality standards over time.
Finally, achieving consensus on labeling guidelines in a permissionless environment is inherently difficult. Without a central authority to enforce standards, disagreements on edge cases can stall progress. As Sahara AI notes, structuring rewards to encourage high-quality contributions rather than sheer quantity is essential to long-term success. Without this alignment, the dataset becomes a commodity of volume, not value.
No comments yet. Be the first to share your thoughts!