Define your data labeling requirements
Before choosing a tokenomics model, you must define the scope of the labeling task. The complexity of your data dictates whether a simple bounty system suffices or if a decentralized platform with smart contract verification is necessary. High-stakes AI models require stricter quality controls than simple categorization tasks.
Start by identifying the data type and labeling granularity. Is this binary classification, object detection, or natural language processing? For instance, ERC-20 tokens are often leveraged in decentralized platforms to incentivize precise, multi-step labeling workflows where accuracy is critical. Determine the volume of data and the expected turnaround time. This information helps you calculate the token reward per label, ensuring it is high enough to attract quality contributors but low enough to remain sustainable.
Next, define the quality assurance protocol. Will you use consensus voting, where multiple labelers annotate the same item? Or will you rely on expert review? Your requirements should specify the acceptable error rate and the mechanism for resolving disagreements. Clear requirements prevent scope creep and ensure that the token incentives align with the actual value of the labeled data.
Select a blockchain-based labeling platform
Choosing the right infrastructure is the first step in building a token-incentivized data labeling workflow. You generally have two paths: joining an existing decentralized platform or building a custom smart contract solution. The decision hinges on your need for speed versus control.
Existing platforms like Sapien and Deano offer ready-made infrastructure. Sapien gamifies the labeling experience, using crypto tokens to reward human labelers for accurate notations, while Deano connects annotators directly with vendors through its DAN token system. These platforms handle the complex backend of token distribution and verification, allowing you to focus on model training rather than community management.
Building a custom solution involves writing smart contracts that manage token rewards and data submission. This approach offers full control over the incentive structure and data ownership but requires significant development time and security auditing. For most teams starting out, leveraging an established platform is the faster route to a functional labeling pipeline.
| Feature | Sapien | Deano | Custom Build |
|---|---|---|---|
| Setup Time | Low | Low | High |
| Token Control | Platform-managed | Platform-managed | Full ownership |
| Community Size | Large | Growing | Build from scratch |
| Integration Complexity | API-based | API-based | Full stack |
Configure smart contract incentive structures
Setting up the ERC-20 token distribution mechanism requires defining how rewards flow from the smart contract to the labelers. This structure must balance volume with accuracy to prevent gaming. The Decentralized Data Labeling Platform (DDLP) model demonstrates this by using Ethereum smart contracts to automate payouts based on verified work. The contract acts as the escrow, holding the incentive pool and releasing tokens only when quality thresholds are met.
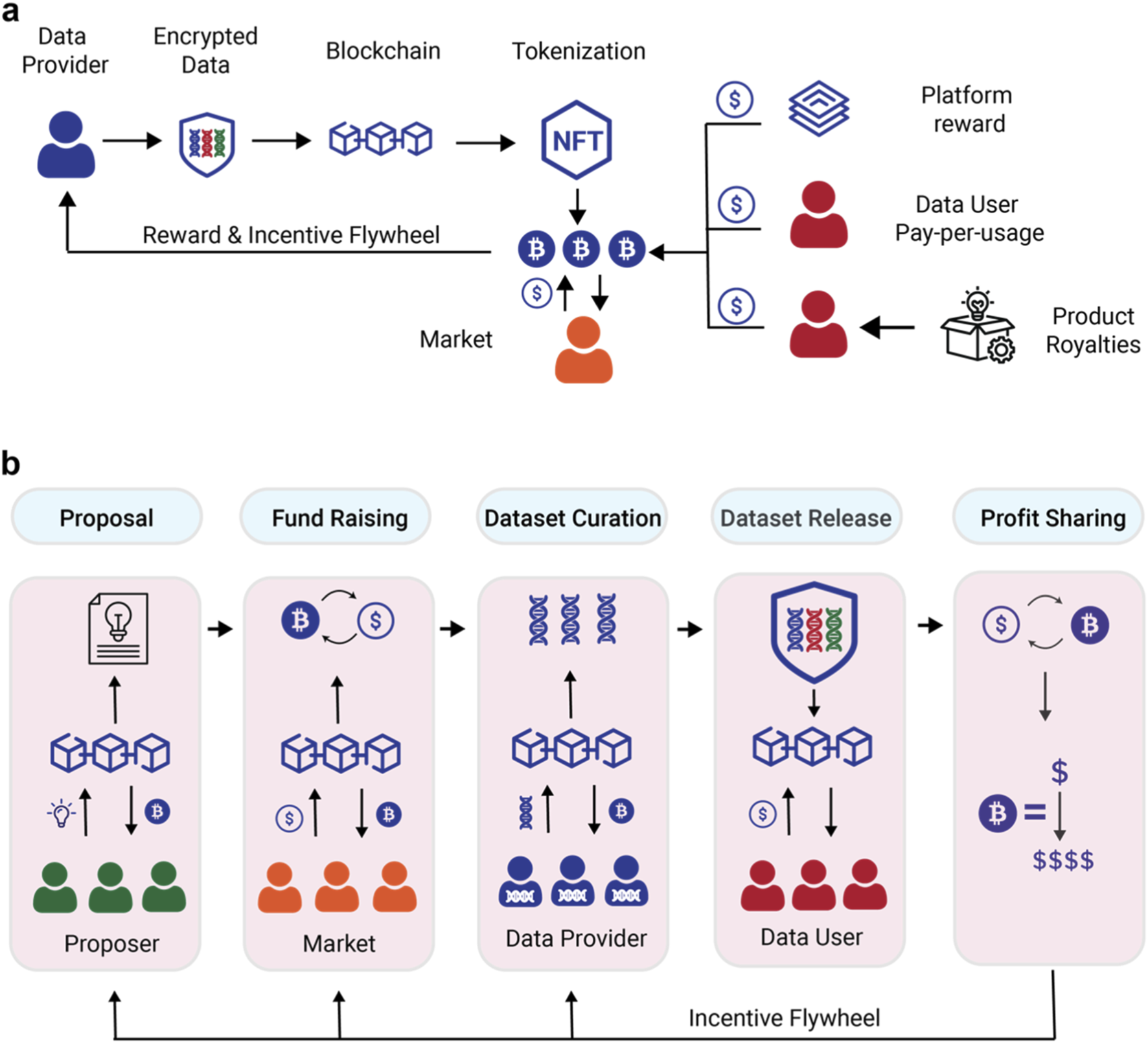
Initialize the ERC-20 token contract with a fixed supply or minting function. Allocate a specific portion of this supply to the labeling incentive pool. This pool is distinct from operational funds and should be large enough to sustain labelers through the initial data collection phase. Ensure the contract has sufficient balance before deploying the labeling logic.
Code the logic that determines reward amounts based on data quality. Instead of a flat rate per task, implement tiers. For example, a label that passes a secondary audit or matches a gold-standard consensus receives a higher token amount. This incentivizes precision over speed. The contract should automatically check the verification status of each labeled batch before triggering a transfer.
Add clauses that penalize malicious behavior. If a labeler’s output is flagged as spam or deliberately incorrect, the smart contract should deduct tokens from their pending rewards. This "slashing" mechanism protects the dataset’s integrity. Define clear rules for when slashing occurs, such as a consensus failure rate exceeding a set percentage, to ensure transparency for all participants.

Connect the data labeling interface to the smart contract’s distribution function. When a batch of labels is approved by the verification module, the contract should automatically execute token transfers to the respective wallet addresses. This removes administrative overhead and ensures immediate, trustless payment. Test the automation with small batches to verify gas costs and transfer speeds.
This configuration ensures that the incentive structure is both robust and fair. By tying rewards directly to verified accuracy, you create a sustainable workflow where high-quality data is the most profitable outcome for labelers. The ERC-20 standard provides the necessary flexibility to adjust these parameters as the dataset grows.
Implement quality control and consensus
Spam and low-quality annotations can quickly drain a token incentive budget. To prevent this, you must enforce multi-annotator consensus and on-chain verification before accepting any data point as final.
Assign multiple annotators
Never rely on a single worker for critical data. Assign each task to at least three independent annotators. This creates a natural redundancy layer where honest workers agree and malicious actors or careless users are identified by their outliers.
Define consensus thresholds
Set a clear agreement rule, such as "two out of three" or majority vote. If the annotators disagree, route the task to a senior reviewer or a higher-stakes consensus round. This ensures that only data with verified agreement is locked into the dataset.
Verify on-chain
Record the consensus result on the blockchain. This provides an immutable audit trail of who contributed what and when they agreed. It also allows the smart contract to automatically distribute tokens to the winning annotators, ensuring transparent and instant payment.
Handle disputes
When consensus fails, use a dispute resolution mechanism. This could involve a third-party expert review or a token-weighted vote among high-reputation workers. This step prevents bad data from slipping through while maintaining trust in the system.
Integrate Labeled Data into AI Training Pipelines
Once the token incentives have secured verified labels, the next step is moving that data into your model training pipeline. This phase bridges the gap between human-in-the-loop verification and automated model updates.
1. Extract Verified Labels
Query your database for labels marked as "verified" or "approved." Filter out any entries that failed quality checks or were flagged during the token reward distribution phase. Ensure only high-confidence data points are selected.
2. Format for Model Ingestion
Convert the extracted labels into the format required by your training framework. Whether using JSONL for language models or TFRecord for computer vision, consistency is critical. Include metadata tags that indicate the source of the label and the token incentive tier, which can help the model weigh data quality during fine-tuning.
3. Validate Data Integrity
Before feeding data into the training loop, run a validation script. Check for duplicate entries, missing fields, or distribution shifts. A quick sanity check here prevents wasted compute cycles on corrupted or biased datasets.
4. Deploy to Training Environment
Push the validated dataset to your training cluster or cloud storage bucket. Trigger the training job using your preferred orchestration tool. Monitor the initial loss curves to ensure the new labeled data is improving model performance as expected.
Frequently asked questions about token incentives
Do token rewards comply with financial regulations?
Token-based incentives exist in a complex regulatory environment. Because tokens can represent financial assets, platforms must ensure their structures do not violate securities laws in the jurisdictions where annotators reside. The IEEE paper on Decentralized Data Labeling Platforms (DDLP) highlights the need for smart contracts that strictly separate incentive mechanics from financial speculation to maintain compliance. Always consult legal counsel to structure token distribution as compensation for labor rather than an investment contract.
How do you prevent token value drops from hurting annotators?
Token volatility can discourage consistent participation if annotators fear their earnings will lose value before they can cash out. To mitigate this, some projects use stablecoins or implement dynamic reward adjustments based on data quality, as noted in Web3 blockchain-driven annotation models. Additionally, gamified platforms like Sapien use token rewards to boost engagement, but they often pair this with immediate fiat conversion options or internal marketplaces to protect annotator income stability.
Do token incentives actually improve annotator retention?
Research suggests that token incentives can boost retention by providing immediate, transparent rewards for accurate labeling. The Deano project at ETHGlobal demonstrates how community tokens create a win-win dynamic, aligning annotator success with vendor needs. However, retention depends on usability; if the process of claiming or converting tokens is friction-heavy, annotators will leave. The key is balancing the novelty of crypto rewards with a seamless user experience that doesn't distract from the labeling task itself.
No comments yet. Be the first to share your thoughts!