Define the labeling scope and token economics
Before writing a single line of smart contract code, you must define the technical boundaries of your labeling task and the economic incentives that will drive participation. This phase establishes the contract between your platform and the labelers, ensuring that the token rewards accurately reflect the complexity and value of the data being annotated.
Start by categorizing the data type and the required annotation precision. Are you dealing with simple binary classification or complex multi-label entity extraction? The granularity of the task directly dictates the time required per sample. For instance, bounding box annotation for autonomous driving datasets requires significantly higher cognitive load than sentiment analysis. Define these parameters explicitly in your task specification to avoid ambiguity during the labeling phase.
Next, calculate the token reward structure. The reward must cover the cost of high-quality human labor while maintaining the financial sustainability of the pipeline. If rewards are too low, you will attract low-effort submissions or bots; if they are too high, your burn rate will become unsustainable. Research suggests that token-based systems can dynamically adjust rewards based on data quality, allowing you to pay premiums for high-confidence annotations while reducing costs for trivial tasks [[src-serp-3]].
Consider the token standard and distribution mechanism. Most decentralized data labeling platforms, such as the Decentralized Data Labeling Platform (DDLP) introduced in recent IEEE research, leverage ERC-20 tokens for their flexibility and compatibility with existing DeFi ecosystems [[src-serp-1]]. This allows for seamless integration with wallets and exchanges, making it easier for labelers to cash out or stake their earnings.
Finally, establish the verification and dispute resolution mechanism. How will you handle incorrect labels? Will you use a consensus model where multiple labelers annotate the same data point, or rely on a hierarchical review system? Define these rules upfront to maintain data integrity and trust in your incentive layer.
Deploy the smart contract for reward distribution
The incentive layer is the mechanism that rewards participants for securing the network and validating transactions. In a token-incentivized data labeling pipeline, this layer ensures that labelers act honestly by automatically distributing tokens upon verification. This section outlines the technical steps to deploy an ERC-20 token and the smart contract logic that automates these payments.
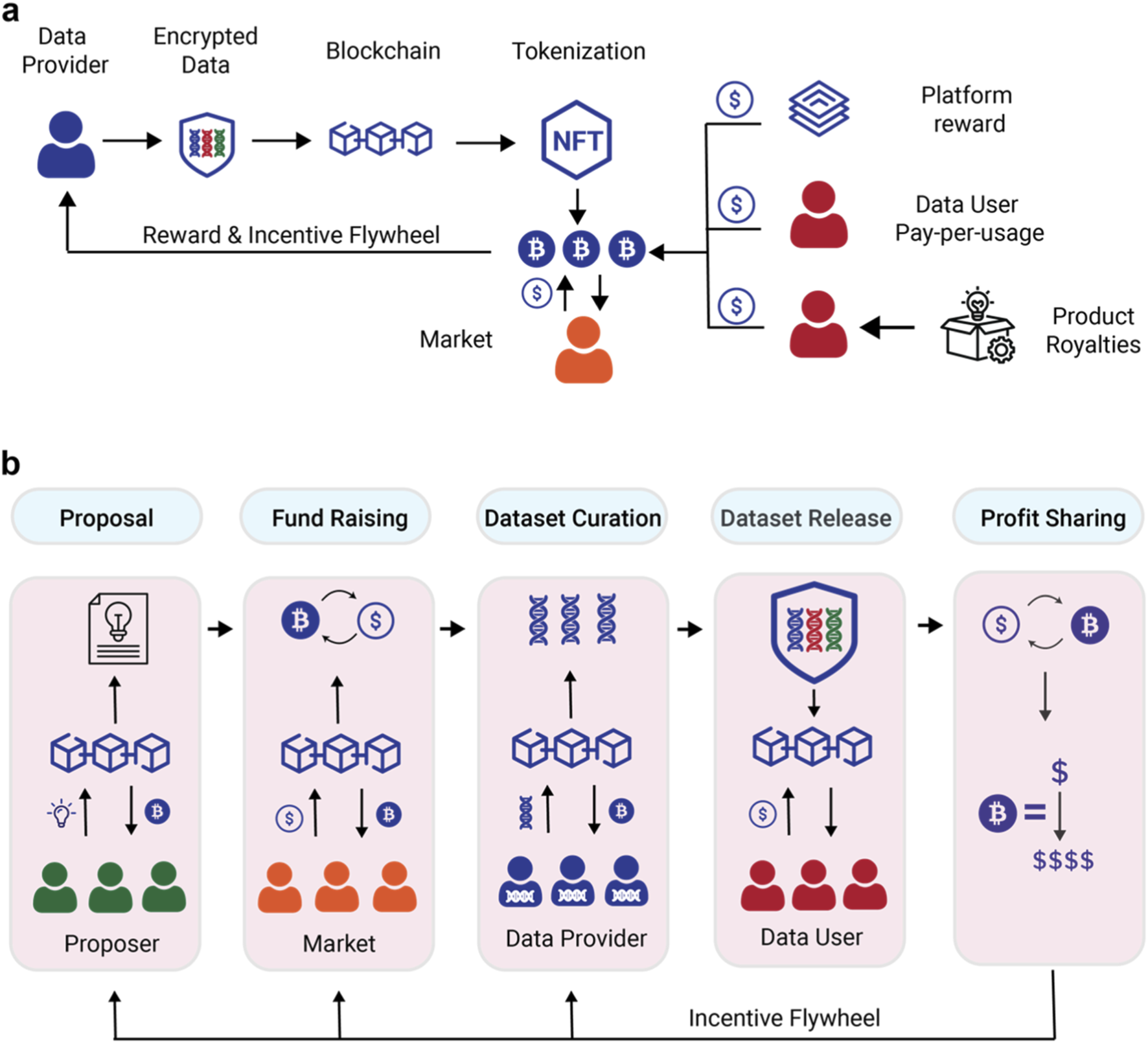
Start by defining the ERC-20 token that will serve as the reward currency. Use OpenZeppelin’s standard implementation to ensure compatibility with wallets and exchanges. Set the token name, symbol, and total supply. The total supply should reflect the budget allocated for the labeling campaign, ensuring that the token has sufficient value to incentivize participation without causing inflationary pressure.
Develop a smart contract that manages the distribution logic. This contract must hold the ERC-20 tokens and distribute them to labelers based on verified work. Include functions for verifyWork and claimReward. The verifyWork function should only be callable by an authorized oracle or verification module, ensuring that rewards are only released for high-quality, validated data labels.
Connect the smart contract to your data labeling pipeline’s verification system. When a batch of labels is verified, the pipeline should call the verifyWork function on the smart contract. This function updates the internal ledger of pending rewards for the specific labeler. This step is critical for maintaining trust, as it decouples the payment process from the data handling process, reducing the risk of fraud.
Deploy the contracts to the Ethereum network using a development environment like Hardhat or Foundry. Verify the source code on Etherscan to ensure transparency. Labelers can then interact with the contract to claim their rewards. For initial testing, deploy to a testnet like Sepolia to validate the flow of tokens and verification logic before moving to mainnet.



As an Amazon Associate, we may earn from qualifying purchases.
Integrate quality control and consensus mechanisms
Preventing fraud in a token-incentivized system requires moving beyond simple payment distribution. You must embed automated validation and multi-annotator consensus directly into the workflow. This approach ensures that data accuracy is verified before tokens are released, aligning the economic incentives with the technical reality of high-quality labeling.
Automate validation scripts
Before human annotators submit their work, run automated checks to catch obvious errors. These scripts should verify format compliance, detect outlier labels, and flag potential bot activity. By filtering out low-effort submissions early, you reduce the noise that consensus mechanisms must later resolve. This step is critical for maintaining the integrity of the dataset without incurring excessive token costs for invalid work.
Implement multi-annotator consensus
No single annotator should determine the final label for a data point. Assign each task to at least three independent annotators. The system then compares their outputs against a predefined agreement threshold. If the majority agrees, the label is accepted, and tokens are distributed. If the results diverge, the task is flagged for review by a senior expert or a trusted validator. This redundancy makes it economically unviable for bad actors to game the system, as they would need to collude across multiple independent nodes to produce fraudulent data consistently.
Dynamic reward adjustment
Token rewards should not be static. As noted in industry analyses of blockchain-driven AI data annotation, systems can dynamically adjust rewards based on data quality and annotator history. Annotators with a high track record of accurate consensus should receive higher per-task rewards, while those with frequent disagreements may face reduced payouts or temporary suspension. This creates a self-correcting ecosystem where quality is directly correlated with compensation, encouraging long-term participation from reliable contributors.
Address GDPR and data privacy compliance
Token-incentivized data labeling introduces a specific legal risk: the permanent, immutable nature of blockchain ledgers. While smart contracts can efficiently distribute ERC-20 tokens to labelers, they cannot automatically delete data. This creates a conflict with GDPR’s right to erasure and data minimization principles. You must architect your pipeline so that the incentive layer (tokens) and the data layer (labels) are strictly separated.
Follow this sequence to ensure compliance before deploying your pipeline:
By decoupling the incentive mechanism from the data storage, you can leverage the efficiency of token-based rewards while maintaining strict adherence to privacy regulations. This architecture ensures that token distribution does not compromise the confidentiality or integrity of the labeled data.
Launch the platform and manage annotator onboarding
With the smart contracts verified and the data pipeline ready, the final step is activating the network. This phase shifts the focus from technical deployment to human operations, ensuring annotators can securely access the platform and understand how their contributions translate into token rewards.
Begin by distributing wallet setup instructions to your initial cohort of annotators. Since many potential contributors may be new to Web3, provide clear, step-by-step guides for creating and securing non-custodial wallets. Integrate a simple on-ramp mechanism or provide a small initial token grant to cover gas fees, removing the friction of upfront costs. Projects like Deano demonstrate that when annotators are part of a community with clear token incentives, participation and data quality improve significantly.
Once wallets are configured, distribute a small batch of test data. This dry run allows you to validate the entire workflow: data ingestion, labeling interface responsiveness, and the automated distribution of rewards upon submission verification. Monitor this test phase closely to identify bottlenecks in the user experience before scaling to full production.

Pre-launch readiness checklist
-
Deploy and verify smart contracts on the testnet or mainnet
-
Distribute wallet setup guides and initial gas subsidies
-
Onboard the first cohort of annotators
-
Run a test data cycle to validate reward distribution logic
-
Confirm data integrity and annotation quality in the test batch
Frequently asked questions about token incentives
How do token rewards work in data labeling?
The incentive layer of a blockchain is responsible for rewarding participants, such as validators or labelers, for securing the network and validating transactions. By distributing tokens, the system ensures that contributors act honestly and maintain the quality of the labeled data. This mechanism aligns the economic interests of the labelers with the health and accuracy of the dataset.
Are there costs associated with token incentives?
Yes. Every transaction on the blockchain requires a gas fee to process the reward distribution. Labelers must account for these network costs when calculating their net earnings. Additionally, token values can fluctuate, meaning the fiat value of rewards may change between the time labeling is completed and the tokens are claimed or sold.
Can I withdraw my token rewards immediately?
Withdrawal depends on the smart contract’s vesting schedule. Some projects release tokens immediately after verification, while others require a waiting period to prevent fraud. Always check the specific terms of the data labeling platform before starting work to understand when and how you can access your earnings.
No comments yet. Be the first to share your thoughts!