The economics of decentralized labeling
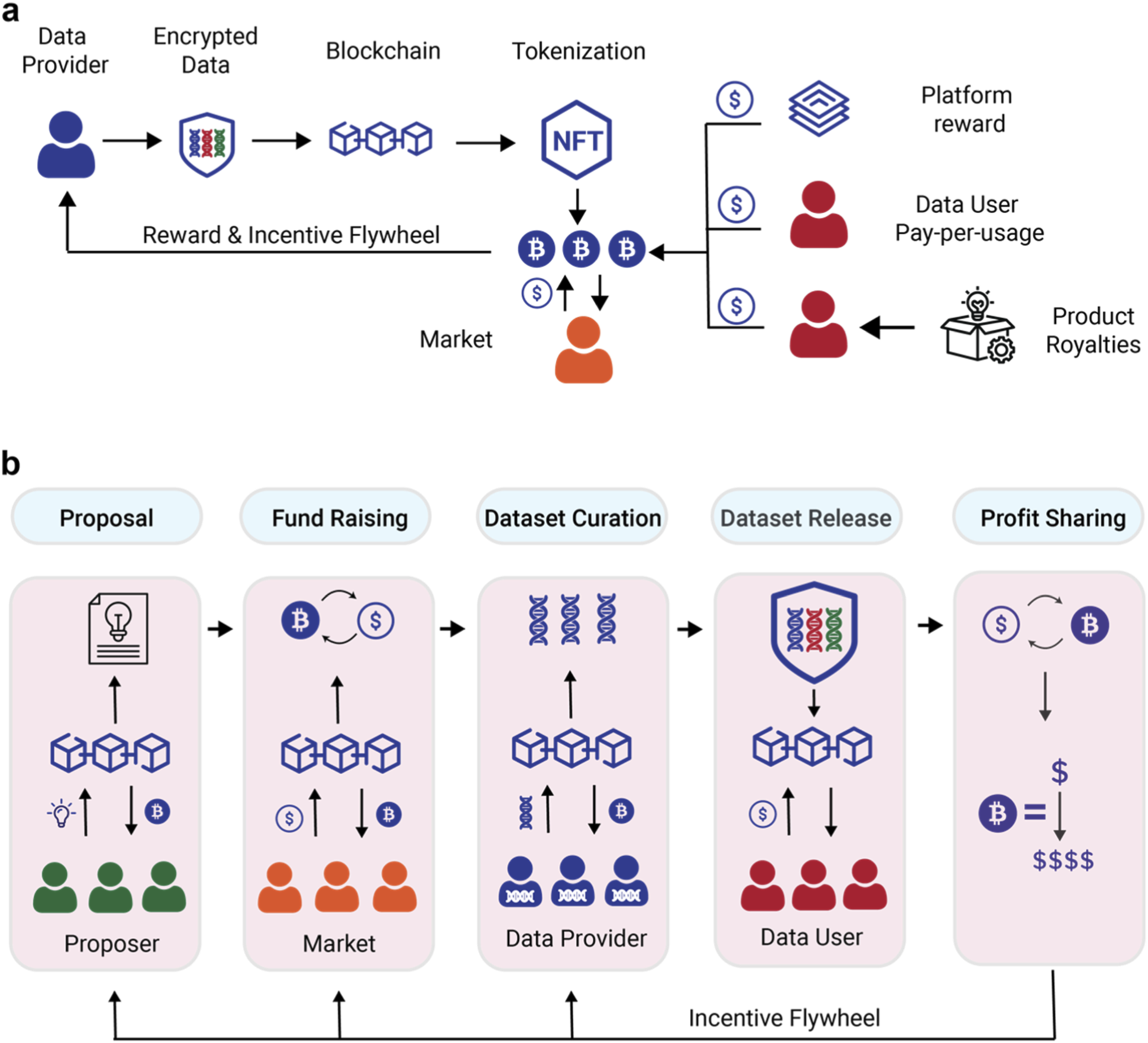
Token-incentivized data labeling replaces the traditional centralized labor arbitrage model with a blockchain-based incentive layer. In this architecture, smart contracts manage the distribution of rewards, allowing projects to tap into a global, on-demand workforce without the overhead of fixed payroll or geographic constraints. This shift transforms data annotation from a static operational cost into a dynamic, market-driven utility.
The core mechanism relies on ERC-20 tokens to reward contributors for high-quality work. As detailed in IEEE research on Decentralized Data Labeling Platforms (DDLP), this approach solves the scalability issues inherent in centralized systems by using Ethereum smart contracts to verify and distribute payments instantly. This ensures that contributors are compensated fairly and immediately, reducing the churn and fraud that often plague traditional crowdsourcing platforms.
This model also introduces dynamic quality control. Unlike static contracts, token rewards can be adjusted in real-time based on data quality metrics. If a contributor’s output meets higher accuracy thresholds, the system automatically increases their reward rate. This creates a self-correcting ecosystem where quality is financially incentivized, aligning the interests of the data providers with the AI developers who need clean, reliable training data.
To understand the financial implications of this shift, it is essential to look at the broader market context. The value of the underlying infrastructure tokens often correlates with the demand for AI data services. The following chart illustrates the recent performance of key blockchain infrastructure assets, providing a baseline for understanding the volatility and growth potential of this sector.
Platform comparison: token mechanics and payout structures
Selecting a token-incentivized labeling platform requires aligning the token model with your specific data constraints and quality thresholds. The current market is dominated by three distinct approaches: Sapien’s gamified ERC-20 model, Deano’s community-driven annotation framework, and the IEEE-backed Decentralized Data Labeling Platform (DDLP) which leverages smart contract verification.
The primary differentiator is not just the token type, but the mechanism of quality assurance. Sapien uses a gamified interface where accuracy directly impacts token rewards, appealing to high-volume, low-complexity tasks. Deano focuses on a community of annotators incentivized by DAN tokens, offering a more curated approach for specialized datasets. DDLP, detailed in IEEE research, employs Ethereum smart contracts to automate validation, reducing the need for manual oversight but requiring higher technical integration.
The following comparison highlights the structural differences between these platforms, focusing on payout mechanisms and target data types.
| Platform | Token Model | Payout Mechanism | Target Data | Quality Assurance |
|---|---|---|---|---|
| Sapien | ERC-20 (SAPI) | Gamified accuracy scores | Image classification, NLP | Consensus voting |
| Deano | DAN Tokens | Community-verified annotations | Text, Audio | Peer review |
| DDLP | ERC-20 (Custom) | Smart contract verification | Structured, Tabular | Automated validation |
For CTOs evaluating these options, the choice often hinges on the trade-off between automation and curation. Sapien offers speed through gamification, Deano provides depth through community expertise, and DDLP delivers rigor through cryptographic verification. Understanding these mechanics is essential for calculating the true ROI of token-based labeling, as the cost of token inflation must be weighed against the savings in manual quality control.
Quality assurance in tokenized datasets
Traditional data labeling relies on centralized oversight, where a single entity validates the ground truth. In decentralized systems, quality assurance shifts from human supervision to cryptographic consensus and smart contract logic. This transition introduces a new risk profile: the potential for Sybil attacks or coordinated manipulation of the labeling pool.
To mitigate these risks, platforms like the Decentralized Data Labeling Platform (DDLP) employ Ethereum smart contracts to automate validation. Rather than relying on a single auditor, the system uses consensus mechanisms where multiple independent labelers must agree on a data point’s classification. Payments are only released when the smart contract verifies that the label meets predefined quality thresholds, ensuring that incentives are tied directly to accuracy rather than volume.
This method creates a self-correcting ecosystem. If a labeler consistently provides low-quality data, their reputation score drops, reducing their ability to earn tokens in the future. This reputation-based filtering is more robust than traditional methods because it is transparent and immutable. However, it requires careful calibration of token rewards to prevent "gaming" the system, where users collude to inflate scores without performing genuine work.
The integrity of the dataset depends on the economic security of the token model. If the cost of attacking the network (e.g., buying enough tokens to sway consensus) is lower than the potential gain from corrupting the data, the system fails. Therefore, the token’s value must be sufficiently high to deter bad actors, creating a financial barrier to entry that traditional crowdsourcing platforms cannot match.
Financial mechanics of token incentives
The economic viability of token-incentivized data labeling hinges on the interplay between token volatility, gas fees, and marginal cost reduction. Unlike traditional centralized outsourcing, where costs are fixed and predictable, decentralized models introduce dynamic pricing that can lower marginal costs but exposes the project to crypto market fluctuations. Understanding these mechanics is essential for accurate ROI forecasting.
Token volatility and reward stability
Token rewards serve as the primary incentive layer, distributing profits instantly and allowing dynamic adjustment based on data quality. However, this introduces significant variance. A spike in token value increases the effective cost per labeled sample, while a downturn may demotitate contributors. Projects must hedge against this by pegging rewards to stablecoins or using algorithmic adjustments to maintain consistent contributor value.
Gas fees and transaction overhead
Every label submission and reward distribution requires an on-chain transaction, incurring gas fees. While layer-2 solutions have reduced these costs, they remain a variable expense that scales with volume. For high-frequency, low-value tasks, gas fees can erode the marginal cost advantage, making the model less efficient than batch-processed centralized alternatives.
The risk of rework and quality costs
The promise of lower marginal costs is contingent on data quality. Incentive misalignment can lead to "gaming" the system, where contributors prioritize quantity over accuracy. Poor-quality data requires costly rework or filtering, potentially negating the initial savings. Robust verification mechanisms, such as consensus-based validation, are necessary to mitigate this risk, though they add computational and token-based overhead.
Selecting a labeling strategy for 2026
Choosing a labeling strategy requires balancing three constraints: budget, data sensitivity, and quality requirements. Token-incentivized platforms automate payment distribution via smart contracts, ensuring that rewards align with verified accuracy rather than volume alone. This automation reduces overhead but introduces smart contract risk that centralized providers do not carry.
1. Evaluate data sensitivity
If your dataset contains protected health information (PHI) or proprietary trade secrets, a centralized platform with strict SOC 2 compliance is often safer. Decentralized networks distribute data across nodes, which increases transparency but complicates data sovereignty. For high-stakes financial or medical AI, the risk of data leakage in a decentralized model may outweigh the cost benefits.
2. Assess quality requirements
Token-based systems rely on consensus mechanisms to verify labels. If your model requires near-perfect accuracy for critical decision-making, the consensus overhead can slow production. Centralized teams offer direct accountability and faster iteration cycles for complex, nuanced labeling tasks where human judgment is paramount.
3. Analyze budget and scalability
For large-scale, repetitive labeling tasks, token-incentivized platforms offer superior scalability. By leveraging a global workforce of micro-labelers, costs can drop significantly compared to specialized centralized agencies. However, this model assumes sufficient token liquidity and stable reward structures to maintain consistent labor supply.
Map your data against regulatory requirements. If GDPR or HIPAA compliance is non-negotiable, prioritize centralized vendors with audited data centers. Decentralized models require careful legal structuring to ensure data residency and deletion rights are enforced.

Examine the tokenomics of any decentralized platform. High inflation rates can devalue rewards, leading to labeler churn and quality drops. Look for platforms with sustainable emission schedules and clear penalty mechanisms for poor-quality submissions.
Test both models on a small, representative dataset. Compare the cost per accurate label, turnaround time, and error rates. This empirical data will reveal whether the theoretical benefits of decentralization translate to your specific use case.
No comments yet. Be the first to share your thoughts!