Set up the smart contract foundation
Deploying a token-incentivized data labeling workflow requires two core components: an ERC-20 token for reward distribution and a labeling smart contract to manage the verification logic. This architecture ensures that data contributors are compensated automatically upon successful annotation, while maintaining data integrity through decentralized oversight.
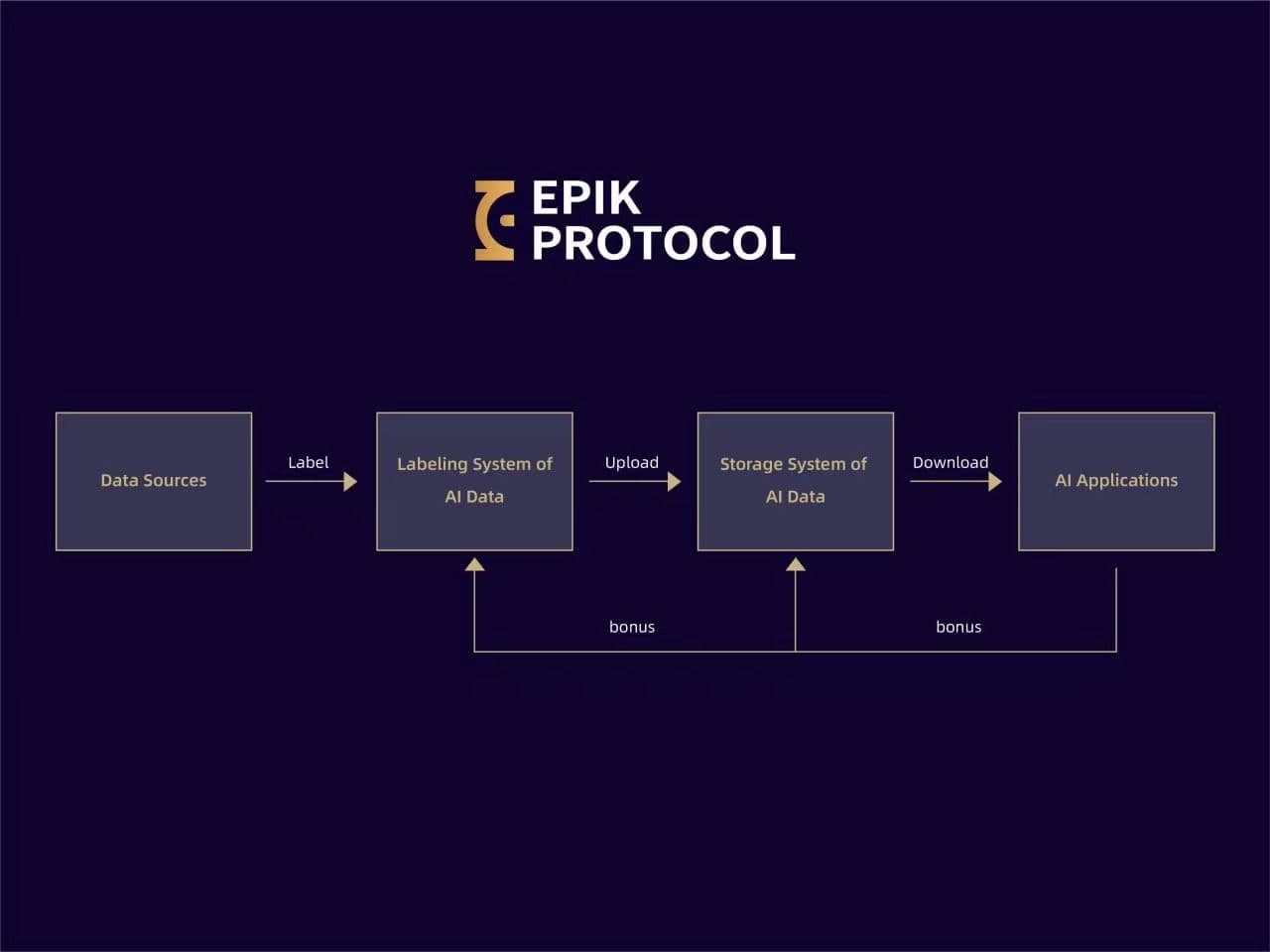
The following steps outline the deployment process based on the Decentralized Data Labeling Platform (DDLP) architecture, which leverages Ethereum smart contracts to solve data quality and incentive alignment issues in AI training pipelines [src-serp-1].
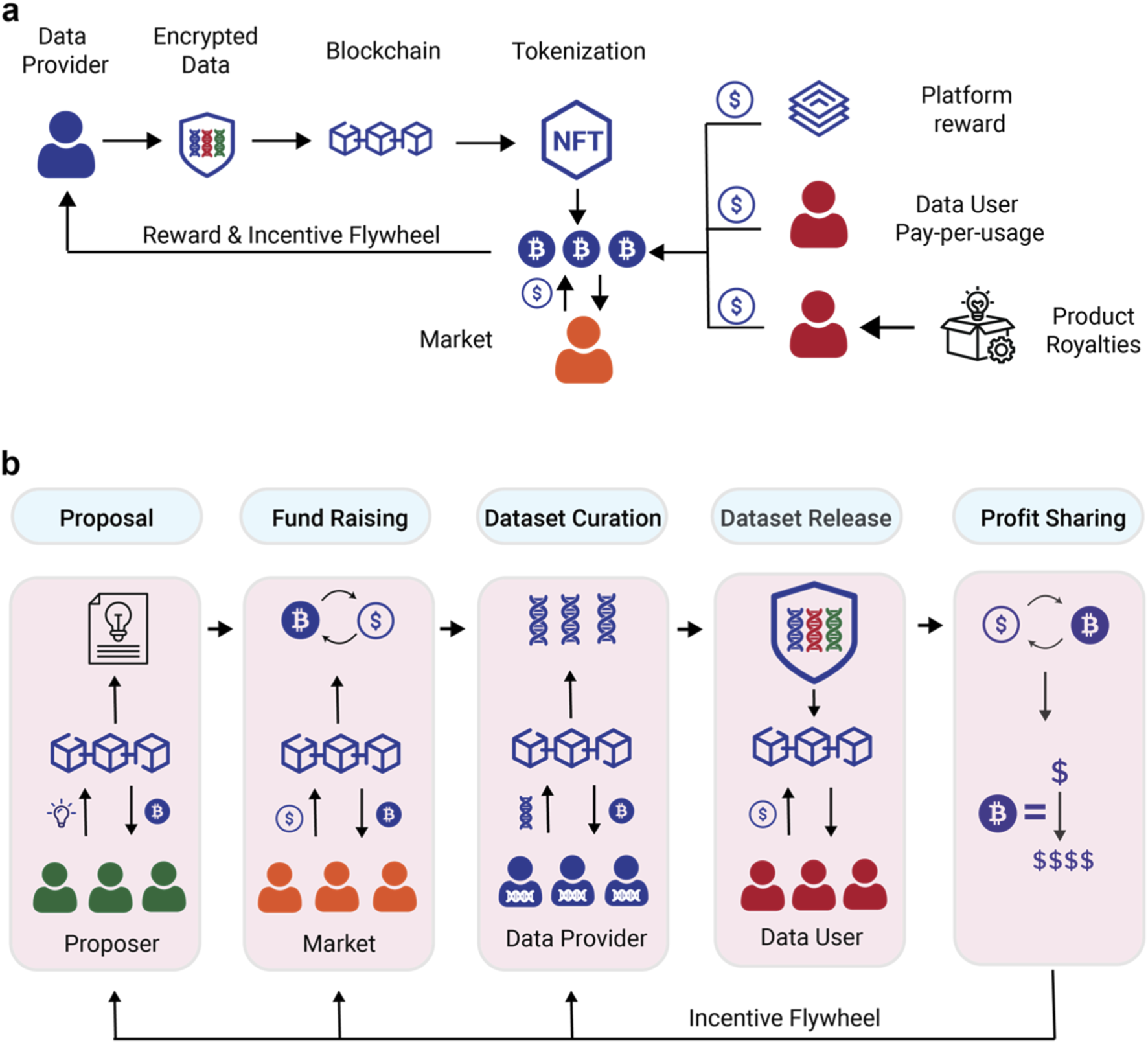
Begin by deploying a standard ERC-20 token contract. This token serves as the currency for incentivizing data labelers. Ensure the token has a fixed supply or a minting mechanism controlled by the labeling contract to prevent inflationary pressures on the reward pool. This token will be held in the labeling contract’s reserve to pay contributors.
Deploy the main labeling contract, which acts as the escrow and verification engine. This contract must accept the ERC-20 tokens as deposits and define the rules for reward distribution. It should include functions to submit annotations, validate them against a consensus mechanism, and automatically transfer tokens to approved labelers.
Code the verification logic within the labeling contract. This typically involves a multi-signature or staking-based validation system where multiple labelers review the same data. Rewards are distributed only when a consensus threshold is met. This step ensures that only high-quality, verified annotations trigger token payouts, maintaining the integrity of the dataset.

Transfer the initial pool of ERC-20 tokens into the labeling contract to fund rewards. Perform extensive testing on a testnet to verify that token transfers, validation logic, and edge cases (such as invalid submissions) function correctly. Once verified, deploy the contracts to the mainnet.
Design the incentive mechanism for annotators
Token incentives must align annotator behavior with data quality. Simple volume-based rewards often lead to spam or low-effort labeling. To prevent this, you need a mechanism that penalizes inaccuracy while rewarding precision.
Start by structuring your smart contracts to automate payments based on predefined conditions. This removes friction and ensures that annotators receive their token rewards immediately upon validation. Platforms like Sapien use blockchain-based rewards to gamify the experience, encouraging labelers to deliver accurate notations rather than rushing through tasks. Similarly, the Deano project incentivizes its community with DAN tokens specifically for accurate data labeling, creating a win-win dynamic for both data vendors and the annotators themselves.
However, paying per label is insufficient. You must incorporate consensus mechanisms. Require multiple annotators to label the same data point. If their answers diverge, the system flags the entry for review or withholds payment. This approach mitigates Sybil attacks, where bad actors create multiple accounts to farm tokens. By tying rewards to consensus and accuracy, you ensure that the token economy drives high-quality data collection, not just quantity.
Finally, consider tiered rewards. Annotators who consistently produce high-accuracy data should earn a higher token rate or access to more complex, higher-paying tasks. This encourages long-term engagement and skill development, turning your labeling workforce into a reliable, quality-focused asset.
Integrate the labeling interface with the blockchain
To make token incentives work, the annotator’s frontend must speak directly to the smart contract. This integration turns abstract blockchain logic into a tangible user experience, ensuring that every label submitted triggers a verifiable reward event. Without this direct connection, the system remains a centralized database rather than a decentralized marketplace.
Connect the wallet
The first step is establishing a persistent link between the user’s browser and their crypto wallet. Use a standard provider like MetaMask or WalletConnect to detect the connected account. The interface should display the wallet address and current balance in real-time, allowing annotators to verify their identity and available tokens before starting work. This step ensures that rewards are attributed to the correct public key without requiring manual address entry for every task.
Verify task eligibility
Before loading a labeling job, the frontend must query the smart contract to confirm the task’s status and the annotator’s eligibility. Check if the specific data batch is active and if the user has met any prerequisite requirements, such as holding a minimum token amount or passing a prior quality check. This validation happens on-chain, preventing fraud and ensuring that only qualified contributors access the most sensitive or high-value datasets.
Submit and track rewards
When an annotator finishes a batch, the interface constructs a transaction to submit the labels. This transaction includes the data hash and the annotator’s signature. Once the transaction is confirmed on the blockchain, the smart contract automatically distributes the pre-defined token reward to the annotator’s address. The frontend should update the UI to show the new token balance and the transaction hash, providing immediate feedback and transparency. This seamless loop of work-to-payment is the core value proposition of token-incentivized data labeling, as it democratizes contributions by ensuring fair, automated compensation for every hour of labor.
Download and set up a secure browser extension wallet. Fund it with the native network token to cover gas fees for initial interactions. This wallet becomes your digital identity for the labeling platform.
Click the "Connect Wallet" button on the labeling interface. Authorize the connection request. The dashboard should now display your wallet address and current token balance, confirming the link is active.

After labeling, click "Submit." A wallet popup will appear to sign the transaction. Wait for the blockchain confirmation. The interface will update to show your new token balance and the transaction hash.
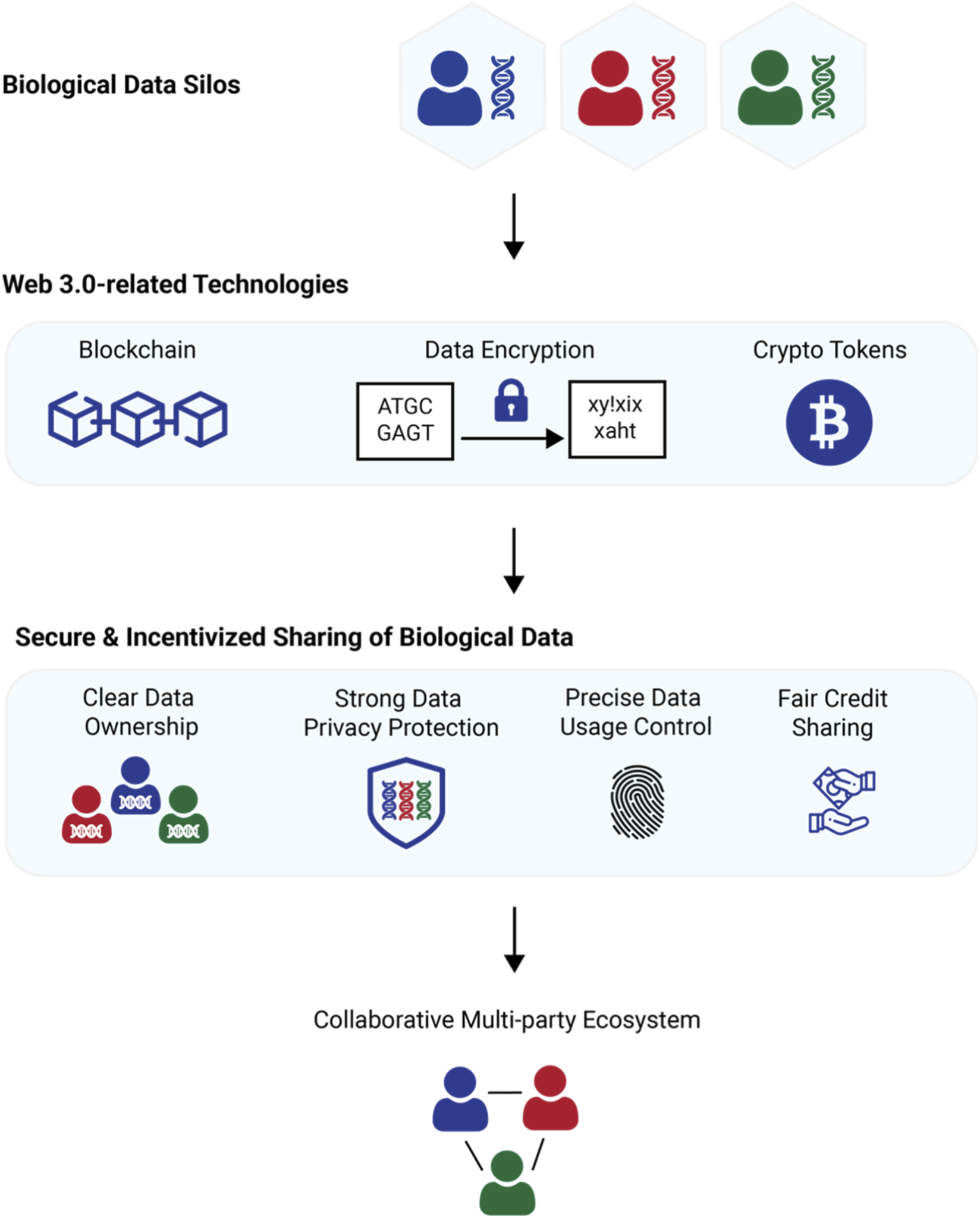
Validate data quality through consensus protocols
Before releasing the full token reward, the system runs a post-labeling verification process. This step ensures that individual annotator submissions meet accuracy standards before they are committed to the blockchain. By requiring multiple annotators to review the same data point, the workflow filters out noise and malicious submissions.
The consensus workflow
- Assign duplicate tasks: The smart contract distributes the same data sample to at least three independent annotators. This redundancy creates a baseline for comparison.
- Collect individual labels: Each annotator submits their classification or bounding box without seeing the others’ work. This prevents confirmation bias and collusion.
- Run the consensus algorithm: The system compares the submissions. If two or more annotators agree, the label is accepted. If the results diverge, the task is flagged for a senior reviewer or a tie-breaking vote.
This approach mirrors the Decentralized Data Labeling Platform (DDLP) architecture described in IEEE research, which uses Ethereum smart contracts to automate these verification steps and enforce token incentives based on verified accuracy [[src-serp-1]].
Token release conditions
Tokens are not released immediately upon submission. They are held in escrow until the consensus check passes. This mechanism penalizes low-quality work by withholding rewards, while ensuring that only validated data enters the AI training pipeline.
Pre-integration checklist
Project managers should verify the following before integrating the labeled data into AI models:
-
Consensus threshold met (e.g., 2/3 or 3/3 agreement)
-
Annotator reputation score above minimum threshold
-
Disputed labels resolved by senior reviewer
-
Smart contract escrow release confirmed
Common Pitfalls in Decentralized Data Labeling
Even with the right infrastructure, decentralized data labeling workflows often fail due to human and economic friction. The most frequent point of failure is low participation. Without a clear, immediate reward structure, annotators abandon tasks that feel ambiguous or unrewarding. Projects that rely solely on altruism or vague "community building" promises rarely sustain the volume needed for high-quality datasets.
Token volatility introduces a second major risk. If the incentive token crashes in value during the labeling period, annotators lose interest, and data quality plummets as users seek more stable platforms. This volatility can render your incentive model ineffective overnight. To mitigate this, consider pegging rewards to stablecoins or using a dual-token system where the utility token is decoupled from speculative price swings.
Poor user experience is the third silent killer. Annotators expect interfaces as intuitive as consumer apps. If the labeling interface is clunky, slow, or lacks clear guidelines, quality drops and churn rises. The friction of connecting wallets, signing transactions, and navigating complex UIs adds up. Streamline the onboarding process and ensure the labeling task itself is the focus, not the blockchain mechanics.
These pitfalls are not inevitable. They require deliberate design choices. By prioritizing stable incentives, intuitive interfaces, and clear communication, you can build a resilient labeling workflow that attracts and retains high-quality contributors.
Frequently asked questions about token incentives
Token-incentivized data labeling introduces unique operational and financial variables that differ from traditional contractor management. Understanding how these systems function technically and legally is essential before launching a workflow.
No comments yet. Be the first to share your thoughts!